
بررسی و پیادهسازی MobileViT
در این پست مقاله MobileViT را بررسی و پیادهسازی میکنیم.
شبکههای عصبی کانولوشنی سبک وزن (CNN)، مدلهای پیشفرض برای انجام وظایف بینایی ماشین بر روی تلفنهای همراه هستند. این شبکهها به خاطر ساختاری که دارند تعداد پارامتر کمتری داشته و برای دستگاههای با منابع محدود مناسبتر هستند. با این حال، این شبکهها امکان ادراک ویژگیها به صورت سراسری را ندارند. برای یادگیری ویژگیهای سراسری، ترانسفورمرهای بینایی مبتنی بر توجه (ViT) به کار گرفته شدهاند. برخلاف CNN ها، ViT ها سنگینوزن هستند و برای اجرا روی دستگاههای با منابع محدود مناسب نیستند.
در سال ۲۰۲۱ مقاله MobileViT توسط نویسندگانی از شرکت اپل منتشر شد که به دنبال یافتن مدلی بود که از مزایا شبکههای CNN و ViT برخوردار باشد و در کنار توانایی ادراک ویژگیها به صورت سراسری، امکان اجرا بر روی دستگاههای با منابع محدود و به طور خاص تلفنهای همراه را داشته باشد. MobileViT توانست با ترکیب ایدههای شبکههای کانوشنی و ترانسفورمری به مدلی دست یابد که از لحاظ دقت و سرعت اجرا از سایر مدلهای ارائه شده تا آن زمان بهتر باشد.
ترانسفورمر بینایی (ViT)
یک مدل استاندارد ViT که در شکل ۱ نشان داده شده است، ورودی را به دنبالهای از تکههای مسطح تغییر شکل میدهد، آن را به یک فضای ثابت d-بعدی نگاشت میکند و سپس با استفاده از L بلوک ترانسفورمر نمایشهای بین تکهها را یاد میگیرد.
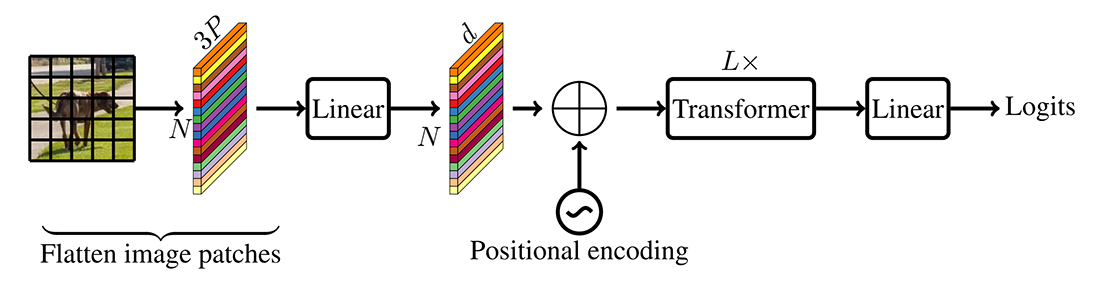
از آنجایی که این مدلها سوگیری استقرایی فضایی (spatial inductive bias) را که در CNN ذاتی است نادیده میگیرند، به پارامترهای بیشتری برای یادگیری نمایشهای بصری نیاز دارند. همچنین، در مقایسه با CNN ها، این مدلها قابلیت بهینهسازی مناسبی ندارند. مدلهای ViT به L2 regularization حساس هستند و برای جلوگیری از بیشبرازش نیاز به افزایش داده (data augmentation) گسترده دارند.
ساختار بلوک MobileViT
ساختار بلوک MobileViT در شکل ۲ نشان داده شده است. این بلوک سعی میکند اطلاعات سراسری و محلی در تصویر را با پارامترهای کمتر مدل کند.
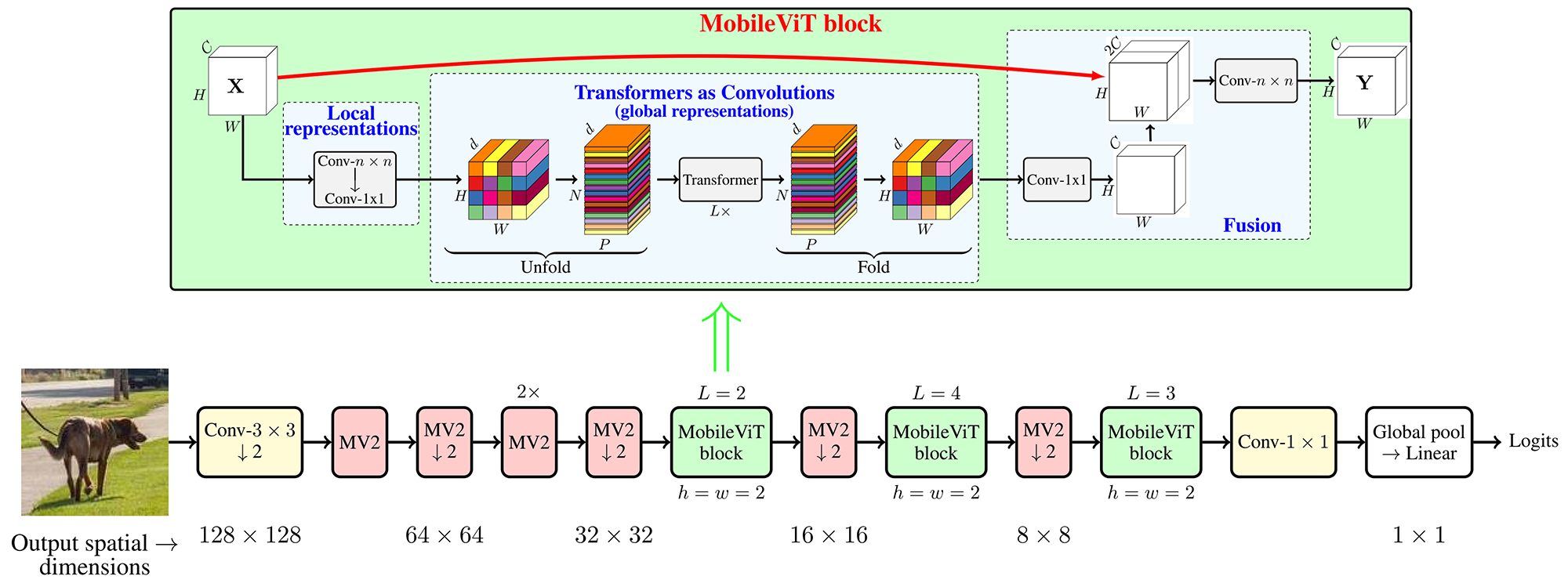
برای یک تنسور ورودی X مشخص، بلوک MobileViT یک لایه کانولوشن استاندارد n×n و به دنبال آن یک لایه کانولوشنی نقطهای (1×1) برای تولید XL اعمال میکند. لایه کانولوشن n×n اطلاعات مکانی محلی را رمزگذاری میکند. سپس کانولوشن نقطهای تنسور بدست آمده را با یادگیری ترکیبهای خطی کانالهای ورودی به فضایی با ابعاد بالا (یا d بعدی، که d بزرگتر از تعداد کانالهاست) نگاشت میکند.
برای آنکه MobileViT امکان یادگیری ویژگیهای سراسری و محلی را به طور همزمان داشته باشد، XL به N تکه (پچ) مسطح غیر همپوشان XU باز (Unfold) میشود. هر پچ شامل P=wh پیکسل میباشد که w و h به ترتیب ارتفاع و عرض هر پچ میباشند. سپس برای هر پیکسل p∈{1,…,P}، روابط بین تکهای توسط ترانسفورمرها اعمال میشود تا XG به صورت زیر بدست آید:
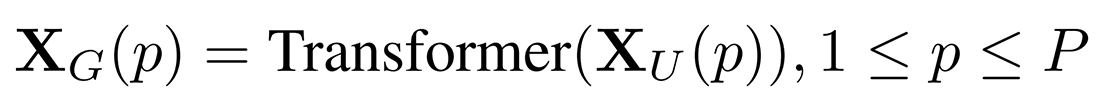
برخلاف ViT ها که ترتیب مکانی پیکسلها را از دست میدهند، MobileViT نه ترتیب پچها و نه ترتیب مکانی پیکسلها داخل هر پچ را از دست میدهد. بنابراین، میتوان XG را جمع (Fold) کرد تا XF بدست آید. سپس XF با استفاده از یک کانولوشن نقطهای به فضای کمبعد C (تعداد کانالهای تصویر) نگاشت میشود و از طریق عملیات الحاق با X (ورودی) ترکیب میشود. سپس یک لایه کانولوشن n×n دیگر برای ترکیب این ویژگیهای الحاق شده استفاده میشود.
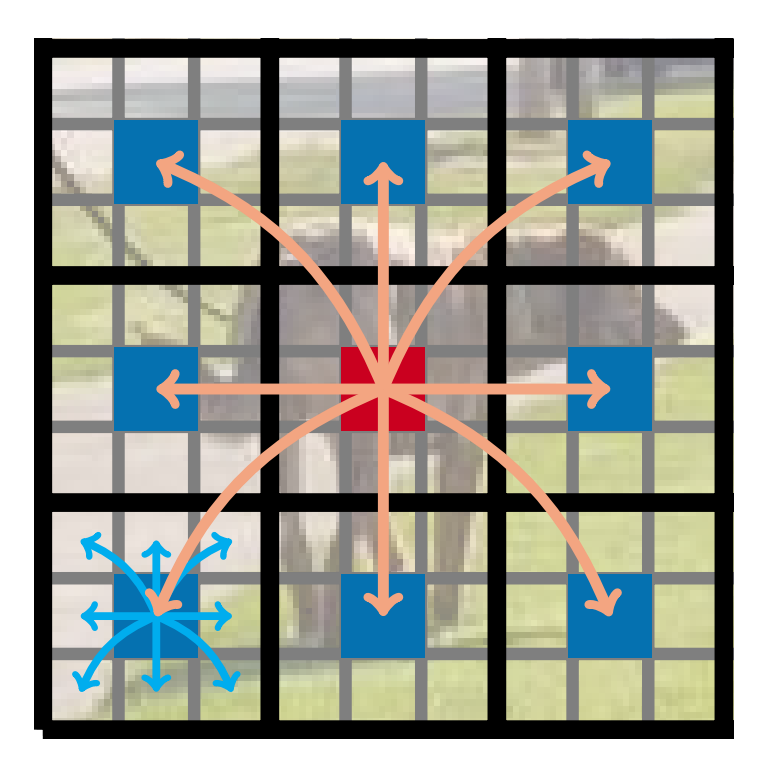
باید توجه داشت که چون XU(p) اطلاعات محلی را با استفاده از کانولوشن و XG(p) اطلاعات سراسری را بین تمامی پچها برای پیکسل p-ام رمزگذاری میکند، هر پیکسل در XG میتواند اطلاعات همه پیکسلهای X را رمزگذاری کند. به بیان دیگر تمامی پیکسلها به اطلاعات یکدیگر دسترسی خواهند داشت. این امر در شکل ۳ بهتر نشان داده شده است.
معماری MobileViT
معماری MobileViT در شکل ۲ نشان داده شده است. لایه اولیه در MobileViT یک کانولوشن استاندارد 3×3 است که به دنبال آن بلوکهای MobileNetV2 (یا MV2) و بلوکهای MobileViT قرار دارند. از Swish به عنوان تابع فعالساز استفاده میشود. مانند مدلهای CNN، از n=3 برای سایز فیلتر در بلوک MobileViT استفاده میشود. بلوکهای MV2 در شبکه MobileViT عمدتاً مسئول کاهش رزولوشن هستند. بنابراین، این بلوکها در شبکه MobileViT کم عمق و با عرض کم هستند.
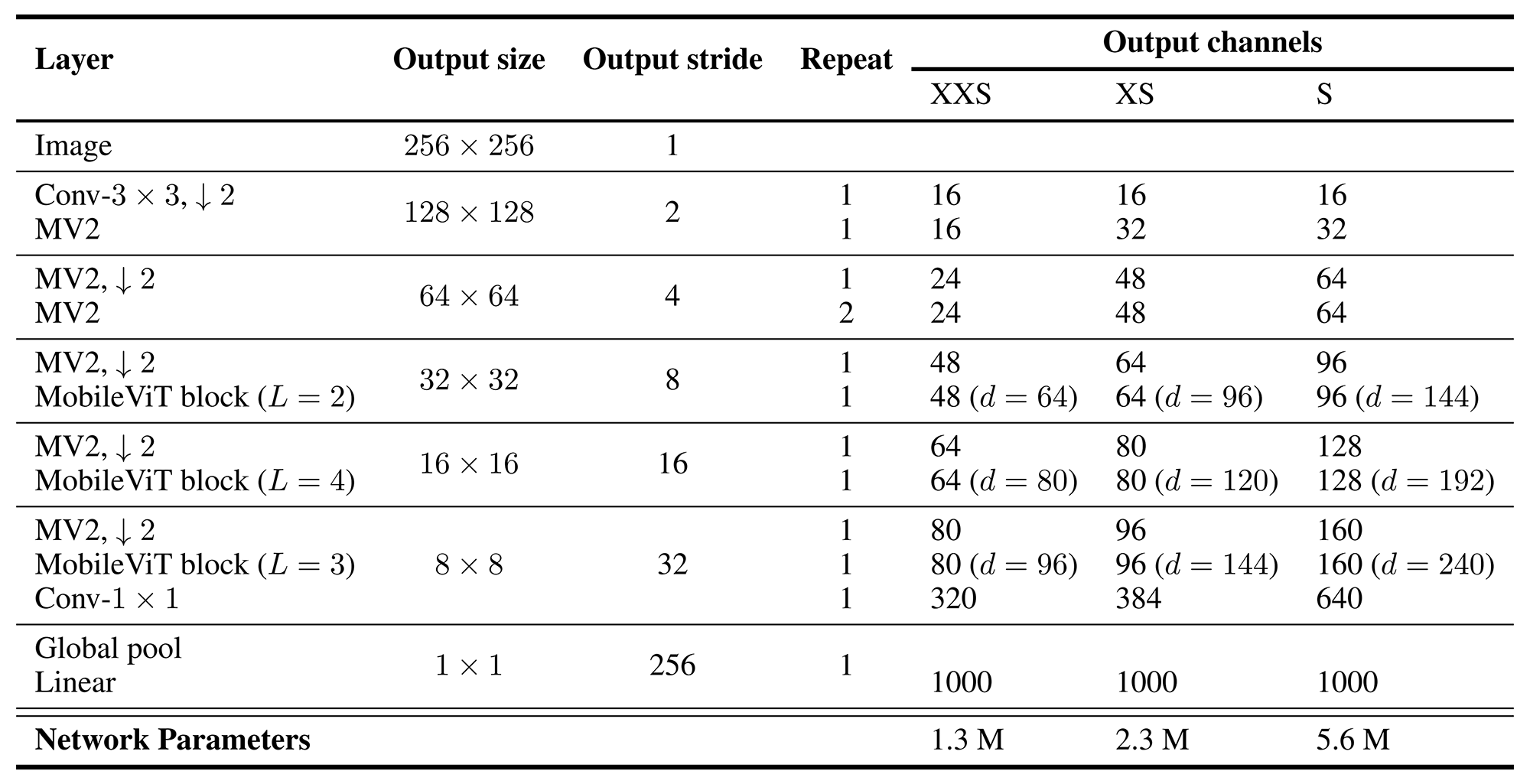
MobileViT در سه نسخه S و XS و XXS ارائه میشود. معماری دقیق این مدلها به همراه تعداد پارامترهای آنها در جدول ۱ نشان داده شده است.
تست کدهای آماده
پیادهسازی آماده MobileViT به همراه وزنهای از پیش آموزش داده شده در کتابخانه timm موجود است. برای استفاده از این مدل آماده و از پیش آموزش داده شده تنها نیاز است تا از دستورات زیر استفاده نمایید.
به کمک دستورات فوق مدل MobileViT لود شده و بر روی یک تصویر دلخواه تست میشود. البته برای ورودی دادن تصویر به مدل نیاز به پیشپردازش تصویر میباشد که این کار توسط تابع transform انجام میشود. در نهایت برچسب پیشبینی شده توسط مدل برای تصویر ورودی، چاپ میشود.
پیادهسازی از پایه
ما برای پیادهسازی MobileViT از پایه از این پست ارزشمند سایت LearnOpenCV کمک گرفتهایم. کدهای زیر همگی بر اساس keras 3 نوشته شدهاند. کراس ۳ قابلیت اجرا بر روی فریمورکهای پایتورچ، تنسورفلو و جکس را دارد. ما در اینجا از بکاند پایتورچ استفاده میکنیم ولی میتوان با تغییر یک خط کد آن را به تنسور فلو یا جکس تغییر داد.
مرحله بعد افزودن import ها میباشد. در این مرحله تمامی کتابخانهها و توابع مورد نیاز به کدمان اضافه میشود.
پیشنیازها
قبل از ادامه کار نیاز است تا یک تابع ضروری معرفی شود. تابع make_divisible مقدار v را طوری تنظیم میکند که بر مقسومعلیه تقسیم شود، و اطمینان حاصل میکند که مقدار آن کمتر از min_value نمیشود و بیش از ۱۰ درصد از v کاهش نمییابد. این کار باعث اطمینان از سازگاری با الزامات سختافزاری مانند هستههای تنسور GPU میشود.
اکنون کلاس ConvLayer تعریف میشود که ترکیبی از سه لایه Conv2D و BatchNormalization و تابع فعالساز Swish میباشد. کلاس ConvLayer در اینجا برای تسهیل انتقال از پایتورچ با شبیهسازی رفتارهای padding و پیکربندی خاص موجود در لایههای کانولوشن پایتورچ طراحی شده است.
سازنده کلاس فوق به ما اجازه میدهد تا چندین پارامتر کلیدی مانند تعداد فیلترها، اندازه کرنل، گام (stride) و استفاده یا عدم استفاده از نرمال سازی دستهای (BN)، تابع فعالساز و بایاسها را تعریف کنیم. همچنین با توجه به مقدار گام، padding مناسب انتخاب میشود. تابع get_config نیز برای سازگاری با تنظیمات دلخواه اضافه شده است.
کلاس پیشنیاز بعدی، کلاس InvertedResidualBlock میباشد که پیادهکننده بلوکهای MobileNetV2 (یا MV2) میباشد.
یکی از ویژگیهای کد فوق آن است که بررسی میکند num_out_channels ارائه شده و expansion_channels محاسبه شده بر ۸ تقسیمپذیر باشند. این کار باعث میشود که عملکرد مدل در سخت افزارهای خاصی بهبود یابد.
بلوک MobileViT
بلوک MobileViT طبق مقاله (توضیحات داده شده در بالا) به صورت زیر پیادهسازی میشود.
بلوک Multi-Head Self-Attention (MHSA)
برای پیادهسازی ترانسفورمر ابتدا نیاز به پیادهسازی بلوک توجه (MHSA) داریم. این کار به صورت زیر انجام میشود.
بلوک ترانسفورمر
این بلوک توسط LayerNormalization و به دنبال آن MHSA و لایه های Dropout و Dense احاطه شده است. این اجزا با هم بلوک ترانسفورمر را تشکیل میدهند.
معماری مدل MobileViT
با توجه به اینکه ما تمام لایهها و بلوکهای مورد نیاز برای ساخت MobileViT را تعریف کردیم، کنار هم قرار دادن کل معماری مدل با ارجاع به جدول ۱ کاملاً ساده است:
تنظیمات مدل MobileViT
برای هر نسخه از MobileViT (S و XS و XXS) یک کلاس پیکربندی ایجاد شده است تا بتوان به سرعت آن مدل را لود کرد و یا تغییر داد. همچنین تابع get_mobile_vit_v1_configs برای دسترسی به این پیکربندیها تعریف شده است.
ساخت مدل MobileViT
با استفاده از تابع کمکی زیر میتوان مدل تعریف شده را ایجاد کرد.
یک نمونه استفاده از این تابع جهت ساخت نسخه XXS از مدل را در زیر میبینید:
انتقال وزنهای رسمی مدل از پایتورچ به کراس ۳
ابتدا وزنهای از پیش آموزش داده شده مدلهای MobileViT را از ریپازیتوری رسمی آن دانلود میکنیم. سپس به ساخت مدلها طبق دستورات فوق میپردازیم.
اکنون قبل از انجام هر کاری نیاز است به این نکته توجه کنیم که به طور پیشفرض، پایتورچ وزنها را در قالب channel_first ذخیره میکند، در حالیکه تنسورفلو و همچنین کراس از قالب channels_last پیروی میکنند. بنابراین، ما باید این تفاوتها را در طول فرآیند انتقال وزنها در نظر داشته باشیم. در اینجا، باید از سه تفاوت اصلی آگاه باشیم:
- لایههای Dense: در کراس، وزنهای لایههای Dense به صورت
(in_features,out_features)ذخیره میشود، در حالیکه در پایتورچ، وزن لایههای Linear در قالب(out_features,in_features)ذخیره میشود. بنابراین وقتی روی وزنهای پایتورچ حرکت میکنیم، باید آنها را ترانهاده کنیم تا با شکل وزنهای کراس مطابقت داشته باشند. - لایههای کانولوشن: وزنهای کرنل در کراس به فرمت
(kH,kW,inC,outC)ذخیره میشوند، در حالیکه در پایتورچ وزنها به صورت(outC,inC,kH,kW)ذخیره میشوند. برای مطابقت، باید وزنهای پایتورچ را به صورت زیر تغییر دهیم:param.permute(2,3,1,0) - لایههای کانولوشن عمقی (Depthwise): در کراس یک لایه مخصوص برای کانولوشن عمقی وجود دارد که وزنهای کرنل را به صورت
(kH,kW,outC,inC)ذخیره میکند. در مقابل، در پایتورچ لایه مخصوصی برای کانولوشن عمقی وجود ندارد و این کار توسط تنظیم پارامترgroups=inCبرای لایه کانولوشن معمولی انجام میشود. بنابراین وزنها هم مثل لایه کانولوشن معمولی دخیره میشوند. بنابراین برای مطابقت، باید یک عملیات جایگشت به صورت زیر انجام دهیم:param.permute(2,3,0,1)
برای تسهیل فرآیند انتقال وزن، یک کلاس به نام WeightsLayerIterator و دو تابع کمکی تعریف شده است: get_pytorch2keras_layer_weights_mapping و load_weights_in_keras_model.
کلاس WeightsLayerIterator به جز انجام فرآیندهای ذکر شده در بالا، به چند مسئله مهم دیگر نیز رسیدگی میکند. به طور مثال در هنگام انتقال وزنها باید از برخی جفتهای کلید-مقدار در پایتورچ و کراس صرفنظر کرد زیرا هیچ پارامتری ندارند. به عنوان مثال متغیر num_batches_tracked از لایه BatchNormalization در پایتورچ و seed_generator_state در کراس.
تابع get_pytorch2keras_layer_weights_mapping برای کمک به ایجاد یک نگاشت بین لایههای کراس و وزنهای مربوط به آن لایه در پایتورچ طراحی شده است. برای هر جفت وزن، نام لایه کراس را از مسیر وزن استخراج کرده و تمام وزنهای پایتورچ را به عنوان یک لیست ذخیره میکند.
همانطور که در کد فوق مشاهده میکنید ما به کمک این تابع، نگاشتهای مورد نظر برای نسخههای مختلف مدل MobileViT را بدست آوردهایم. سپس تنها کاری که باقی میماند این است که روی هر لایه در کراس حرکت کنیم و از عملیات set_weights برای بازنویسی وزنهای فعلی استفاده کنیم. این کار توسط تابع load_weights_in_keras_model انجام میشود.
تست مدل
برای تست مدل ساخته شده و اطمینان از صحت انتقال وزنها، با کمک دستورات زیر به ارزیابی مدل بر روی دو نمونه تصویر دلخواه میپردازیم.
پیشبینی مدلها به همراه تصاویر داده شده به مدل در شکل ۴ آورده شده است. همانطور که در شکل ۴ پیداست مدلها به درستی توانستهاند کلاس تصاویر ورودی داده شده را پیشبینی کنند.

در بالا قطعه کدهای لازم برای پیادهسازی MobileViT از پایه در محیط کراس ۳ و انتقال وزنهای از پیش آموزش داده شده پایتورچ (از ریپازیتوری رسمی MobileViT) به مدل پیادهسازی شده آورده شد. شما میتوانید کدهای لازم برای پیادهسازی، انتقال وزنها و ارزیابی MobileViT را از گیتهاب دانلود کنید. همچنین میتوانید تمامی کدهای فوق به همراه نتیجه اجرای آنها را در این نوتبوک کولب مشاهده نمایید.
⏱︎ تاریخ نگارش: ۳۰ مهر ۱۴۰۳
دیدگاهها