
بررسی و پیادهسازی MobileViTv2
در این پست قصد داریم به بررسی و پیادهسازی مقاله MobileViTv2 بپردازیم.
یک سال پس از انتشار مقاله MobileViT، نویسندگان مقاله اقدام به ارائه نسخه دوم مدل خود تحت عنوان Separable Self-attention for Mobile Vision Transformers کردند. همانطور که از نام مقاله پیداست ایده اصلی آنها، ارائه مفهومی به نام مکانیزم توجه تفکیکپذیر یا Separable Self-attention میباشد که باعث بهبود سرعت بلوک توجه در ترانسفورمر میشود.
پیچیدگی زمانی مکانیزم توجه چند سر (multi-headed self-attention یا به اختصار MHA) در ترانسفورمرها برابر O(k2) میباشد که k تعداد توکنها (یا پچها) میباشد. علاوه بر این برای پیادهسازی نیاز به عملیاتهای پرهزینه مانند ضرب ماتریسی دستهای (batch-wise matrix multiplication) میباشد که باعث ایجاد تاخیر بر روی دستگاههای با منابع محدود میگردد. مکانیزم توجه تفکیکپذیر (Separable Self-attention) ارائه شده پیچیدگی زمانی خطی یا O(k) داشته و از عملیاتهای ساده عنصر به عنصر (element-wise) برای محاسبه استفاده میکند که آن را برای پیادهسازی بر روی دستگاههای با منابع محدود بسیار مناسب میسازد.
مکانیزم توجه چند سر (multi-headed self-attention)
مکانیزم توجه چند سر (MHA) در شکل ۱ قسمت (a) نشان داده شده است. MHA به ترانسفورمر اجازه میدهد تا روابط بین توکنها را رمزگذاری کند. به طور مشخص، MHA یک ورودی x متشکل از k توکن (یا پچ) d-بعدی را میگیرد. سپس ورودی x به سه شاخه Q (Query)، K (Key) و V (Value) وارد میشود. هر شاخه از h لایه خطی (یا سر) تشکیل شده است که ترانسفورمر را قادر میسازد نماهای مختفی از ورودی را یاد بگیرد. ضرب نقطهای بین خروجی لایههای خطی Q و K به طور همزمان برای تمامی h سر محاسبه میشود و سپس از یک تابع softmax عبور داده میشود تا ماتریس توجه a بدست آید. سپس یک ضرب نقطهای دیگر بین ماتریس a و خروجی لایههای خطی در V محاسبه میشود تا yw بدست آید. سپس خروجیهای h سر در yw، برای تولید یک تنسور با k توکن d-بعدی، با هم concat میشوند. در نهایت این تنسور به لایه خطی دیگری برای تولید خروجی نهایی y داده میشود.
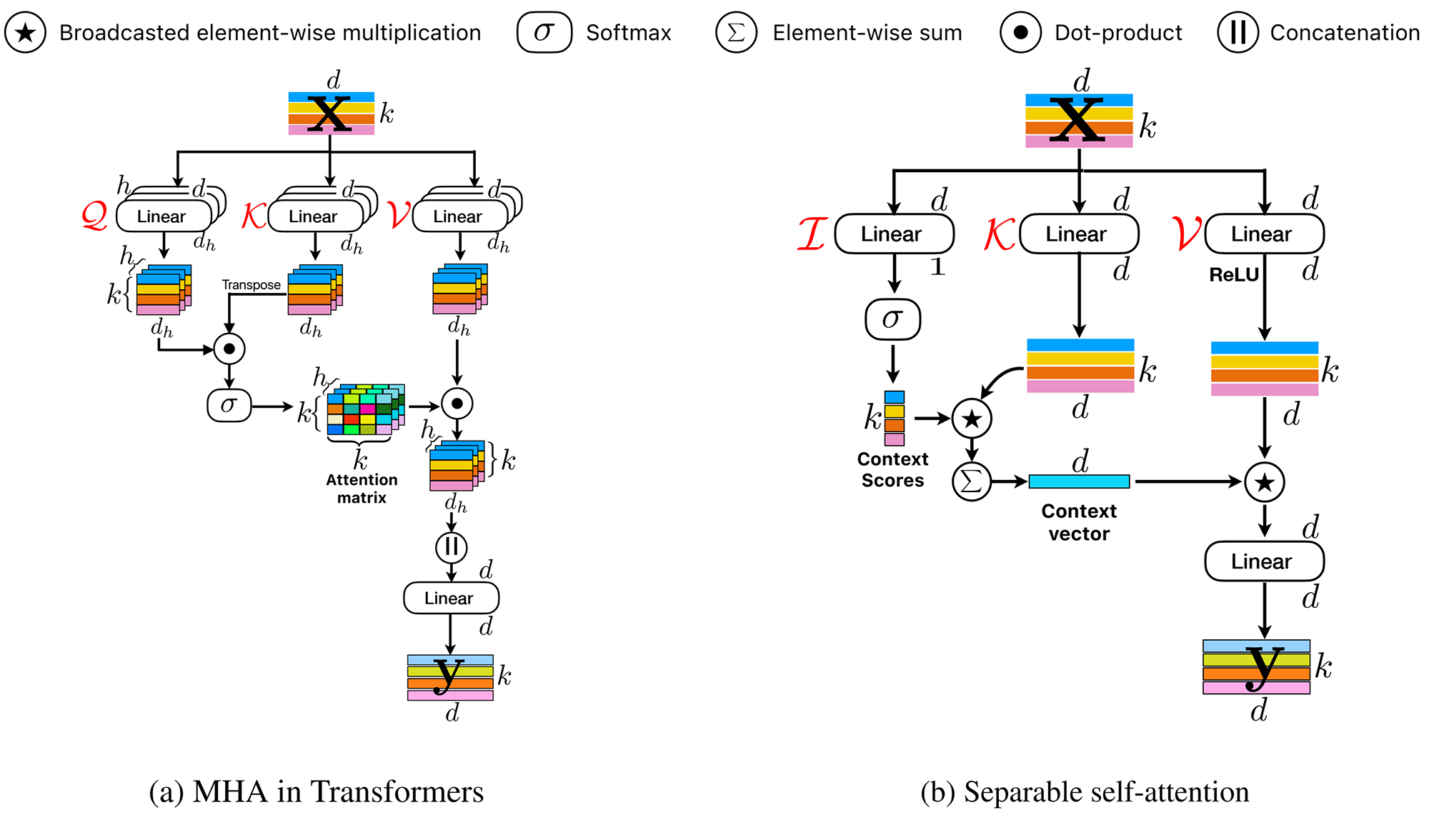
مرتبه زمانی MHA برابر O(k2) میباشد که در مواقعی که تعداد توکنها (یا پچها) زیاد باشد باعث ایجاد گلوگاه در عملکرد مدل میشود. همچنین برای محاسبه MHA از عملیاتهای پرهزینه مانند ضرب ماتریسی دستهای و تابع softmax استفاده میشود که از لحاظ محاسباتی و مصرف حافظه بهینه نیستند.
مکانیزم توجه تفکیکپذیر (Separable Self-attention)
ساختار مکانیزم توجه تفکیکپذیر از MHA الهام گرفته شده است. مشابه MHA، ورودی x با استفاده از سه شاخه پردازش میشود، یعنی I (Input)، K (Key) و V (Value). شاخه ورودی I هر توکن d-بعدی در x را با استفاده از یک لایه خطی با وزنهای WI به یک اسکالر نگاشت میکند (به شکل ۱ قسمت (b) توجه کنید). وزن WI به عنوان گره نهفته L در شکل ۲ بخش (b) عمل میکند. این نگاشت خطی در واقع یک ضرب داخلی است و فاصله بین توکن نهفته L و x را محاسبه میکند که منجر به یک بردار k-بعدی میشود. سپس یک تابع softmax بر روی این بردار k-بعدی اعمال میشود تا مقادیر زمینه cs تولید شود. برخلاف ترانسفورمرهای معمول که مقدار توجه (یا زمینه) را برای هر توکن با در نظر گرفتن همه k توکن محاسبه میکنند، روش ارائه شده فقط مقدار زمینه را با در نظر گرفتن یک توکن نهفته L محاسبه میکند. این امر هزینه محاسبه مقادیر توجه (یا زمینه) را از O(k2) به O(k) کاهش میدهد.
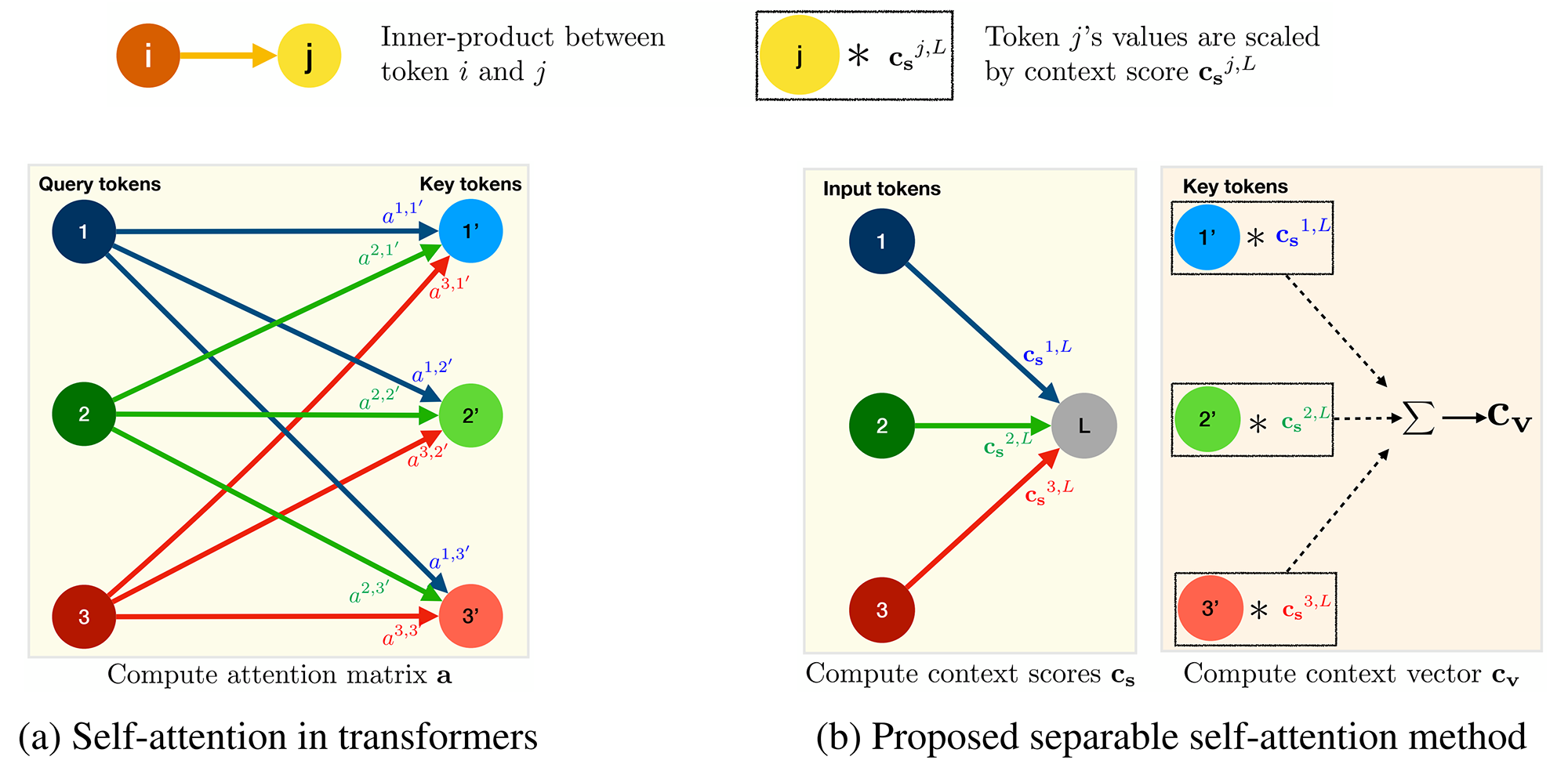
مقدار زمینه cs برای محاسبه بردار زمینه cv استفاده میشود. به طور مشخص، ورودی x با استفاده از شاخه Key با وزنهای WK به صورت خطی به یک فضای d-بعدی برای تولید خروجی xK نگاشت میشود. سپس بردار زمینه cv به عنوان مجموع وزندار xK به صورت زیر محاسبه میشود:
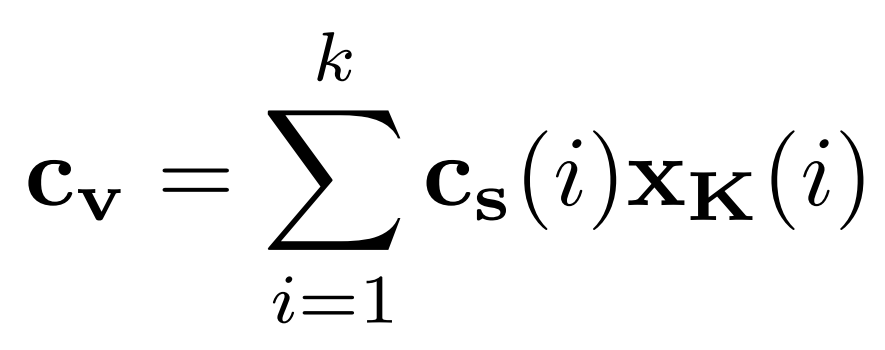
بردار زمینه cv مشابه ماتریس توجه a در ترانسفومرهای معمول است. به این معنا که اطلاعات همه توکنها در ورودی x را رمزگذاری میکند، اما محاسبه آن کم هزینه است.
اطلاعات زمینهای رمزگذاری شده در cv با تمام توکنهای x به اشتراک گذاشته میشود. برای انجام این کار، ورودی x با استفاده از شاخه Value با وزنهای WV به صورت خطی به یک فضای d-بعدی نگاشت میشود. به دنبال آن یک تابع فعالساز ReLU برای تولید خروجی xV آورده میشود. سپس اطلاعات زمینهای در cv از طریق عملیات ضرب عنصر به عنصر پخش شده (broadcasted element-wise multiplication) به xV منتشر میشود. سپس خروجی حاصل به یک لایه خطی دیگر با وزنهای WO داده میشود تا خروجی نهایی y را تولید کند (شکل ۱ بخش (b)).
معماری MobileViTv2
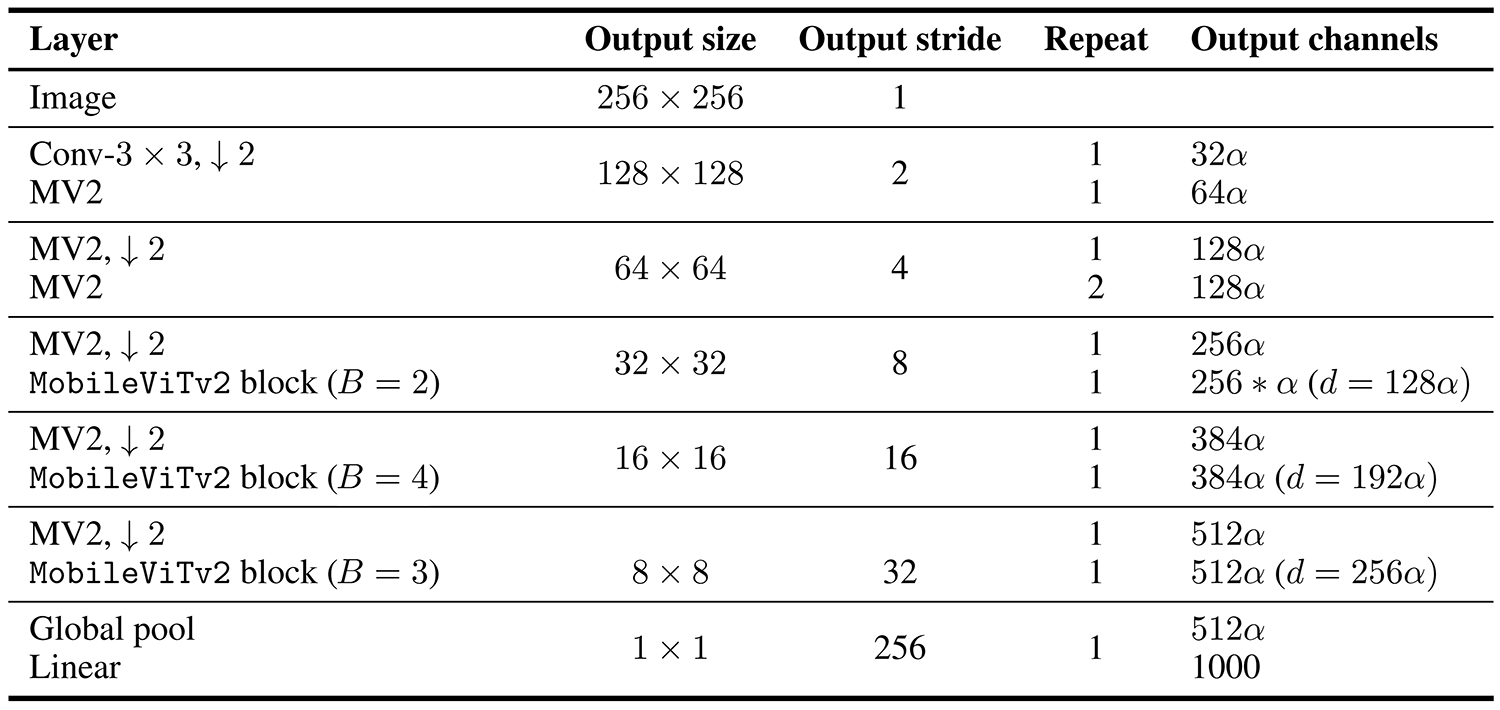
معماری MobileViTv2 در جدول ۱ نشان داده شده است. این معماری شبیه معماری MobileViTv1 است با این تفاوت که بلوک MobileViTv2 جایگزین بلوک MobileViTv1 شده است. بلوک MobileViTv2 در شکل ۳ نشان داده شده است. این بلوک شبیه بلوک MobileViTv1 است با این تفاوت که در آن از مکانیزم Separable Self-attention به جای MHA استفاده شده است. همچنین دیگر از اتصال میانبر و ماژول Fusion استفاده نشده است. برای ایجاد مدلهای MobileViTv2 با پیچیدگیهای مختلف، عرض شبکه با استفاده از ضریب عرض α∈{0.5,2} به طور یکنواخت مقیاسبندی میشود.

پیادهسازی
پیادهسازی آماده MobileViTv2 به همراه وزنهای از پیش آموزش داده شده در کتابخانه timm موجود است. برای استفاده از این مدل آماده و از پیش آموزش داده شده تنها نیاز است تا از دستورات زیر استفاده نمایید.
به کمک دستورات فوق مدل MobileViTv2 (با ضریب عرض α=0.5) لود شده و بر روی یک تصویر دلخواه تست میشود. البته برای ورودی دادن تصویر به مدل نیاز به پیشپردازش تصویر میباشد که این کار توسط تابع transform انجام میشود. در نهایت برچسب پیشبینی شده توسط مدل برای تصویر ورودی، چاپ میشود.
شما میتوانید کدهای لازم برای پیادهسازی و ارزیابی MobileViTv2 با استفاده از فریمورک Keras3 را از گیتهاب دانلود کنید. همچنین میتوانید کدهای رسمی این مدل را در ریپازیتوری ml-cvnets اپل مشاهده نمایید.
⏱︎ تاریخ نگارش: ۷ آبان ۱۴۰۳
دیدگاهها