
بررسی و پیادهسازی MobileNet V2
در این پست قصد داریم به بررسی و پیادهسازی مقاله MobileNet V2 بپردازیم.
در پست قبلی به بررسی معماری و پیادهسازی MobileNet V1 پرداختیم. در این پست مقاله MobileNet V2 را بررسی کرده و به پیادهسازی آن میپردازیم. تعدادی از نویسندگان MobileNet V1 به همراه چند محقق دیگر از گوگل یک سال پس از انتشار MobileNet، نسخه دوم آن را منتشر کردند. آنها در این نسخه با استفاده از مفاهیمی به نام Inverted Residuals و Linear Bottlenecks که در ادامه آنها را بررسی خواهیم کرد، سعی بر بهبود عملکرد مدل دارند.
Linear Bottlenecks (گلوگاههای خطی)
“لایه های گلوگاه خطی در واقع لایههای گلوگاه با فعال سازهای خطی هستند”
مدتها فرض بر این بود که منیفولد مورد نظر در شبکههای عصبی میتواند در یک زیرفضای با بعد کم تعبیه شود. به عبارت دیگر، نمایش دادهای که ما به آن علاقهمندیم میتواند در یک زیرفضای کوچک جاسازی شود. بنابراین، ما میتوانیم به سادگی ابعاد یک لایه را کاهش دهیم تا زمانی که منیفولد مورد نظر را بدست آوریم. با این حال، این فرض درست نیست، زیرا شبکههای عصبی عمیق معمولا از ReLU به عنوان تابع فعالساز استفاده میکنند که اگر ویژگیها در ابعاد پایین باشند، اطلاعات زیادی را از بین میبرد. شواهد تجربی نشان میدهد که استفاده از لایههای غیرخطی در گلوگاه، اطلاعات بیش از حدی را در فضای کمبعد از بین میبرد، حتی اگر به طور کلی، مدلهای گلوگاه خطی نسبت به مدلهای غیرخطی قدرت کمتری داشته باشند. بنابراین اگر منیفولد مورد نظر را کمبعد فرض کنیم، میتوانیم با قرار دادن لایههای گلوگاه خطی در بلوکهای کانولوشنی، این مسئله را حل کنیم.
Inverted Residuals (اتصالات معکوس)
“به استفاده از میانبرها بین گلوگاهها (به جای بلوکهای انبساط)، اتصالات معکوس گفته میشود”
بلوکهای دارای اتصالات معمول (Residual) شامل یک ورودی هستند که با چندین گلوگاه (Bottleneck) و سپس بلوک انبساط (Expansion) دنبال میشوند و میانبرها (shortcuts) بین لایههای ضخیم (لایههایی با کانالهای زیاد) قرار میگیرند. با این حال، MobileNet V2 با الهام از این موضوع که گلوگاهها (Bottlenecks) در واقع تمام اطلاعات لازم را دارند و لایه انبساط (Expansion) صرفاً به عنوان یک تبدیل غیرخطی عمل میکند، به طور مستقیم از میانبرهایی بین گلوگاهها (لایههای نازک) استفاده میکند. نتایج به دست آمده نشان میدهند میانبر بین گلوگاهها (اتصالات معکوس) عملکرد بهتری نسبت به میانبر بین لایههای انبساط (اتصالات معمول) دارد. شکل ۱ این ایده را بهتر نشان میدهد.
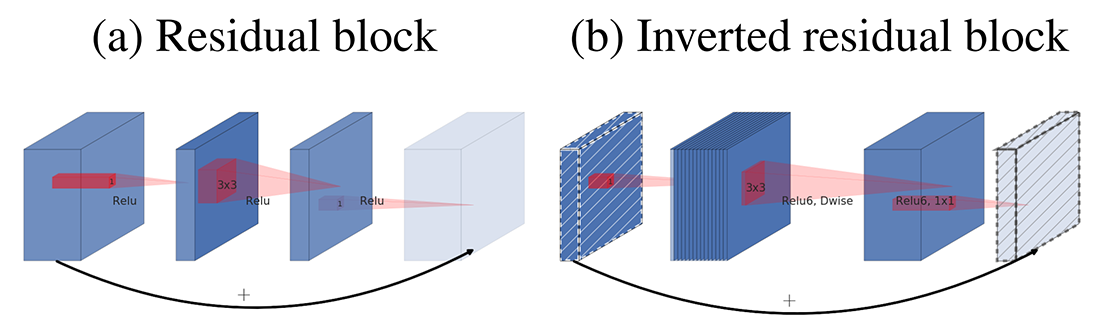
در MobileNet V2 از فعالساز Relu6 به دلیل استحکام آن هنگام استفاده در محاسبات با دقت پایین، به جای Relu استفاده میشود. Relu6 مقادیر بیشتر از ۶ را به ۶ مپ میکند. همچنین در MobileNet V2 همانند MobileNet V1 از فیلترهای کانولوشنی تفکیکپذیر عمقی استفاده میشود.
معماری
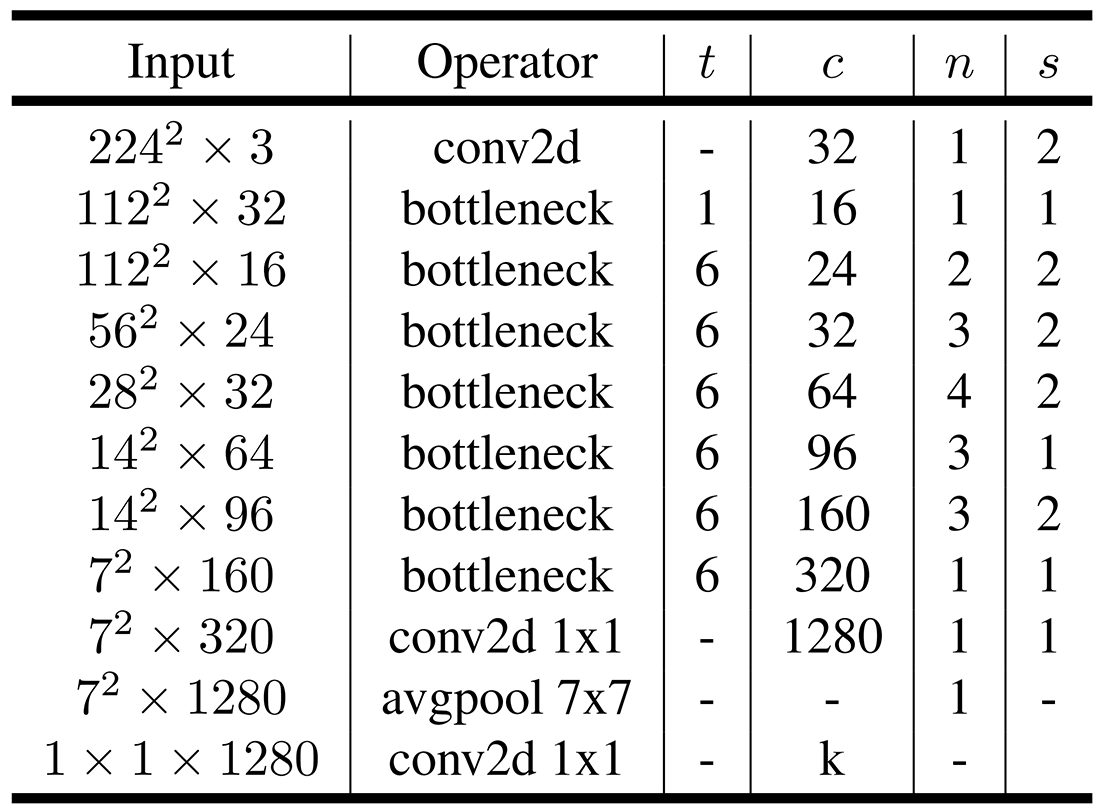
همانطور که پیشتر نیز گقته شد بلوک اصلی در معماری MobileNet V2 گلوگاههای کانولوشنی تفکیکپذیر عمقی با اتصالات معکوس هستند. ساختار دقیق این بلوکها در جدول ۱ نشان داده شده است.

معماری MobileNet V2 شامل لایههای کانولوشنی عادی، بلوک گلوگاه کانولوشنی (طبق ساختار جدول ۱) و کانولوشنهای نقطهای (1×1) میباشد. همچنین در این معماری از لایههای تماما متصل (FC) استفاده نشده است و بنابراین این معماری یک معماری تماما کانولوشنی میباشد. معماری MobileNet V2 را میتوانید در جدول ۲ مشاهده کنید.
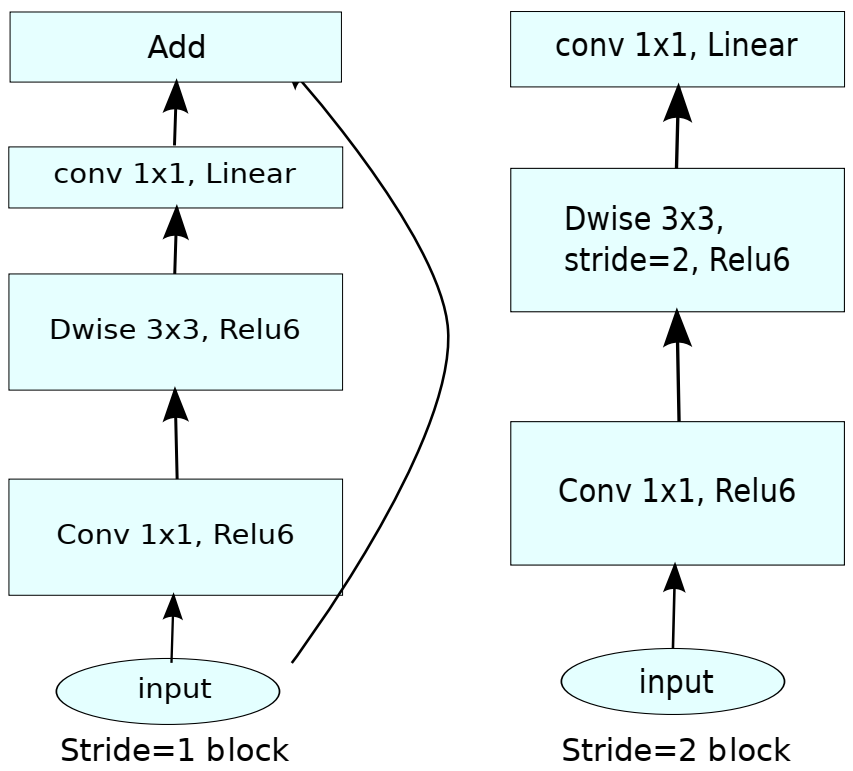
نکته دیگری که باید به آن توجه داشت آن است که در بلوکهای گلوگاه کانولوشنی هرگاه گام s برابر ۱ باشد از اتصالات استفاده میشود و هر گاه گام s برابر ۲ باشد از اتصالات استفاده نمیشود. این امر در شکل ۲ به خوبی نشان داده شده است.
پیادهسازی
مدل MobileNet V2 توسط محققین گوگل توسعه یافته است و بنابراین پیادهسازی آن نیز در فریمورک تنسورفلو موجود است. برای استفاده از این مدل آماده و از پیش آموزش داده شده تنها نیاز است تا از دستورات زیر استفاده نمایید.
در قطعه کد فوق ابتدا مدل MobileNet V2 با وزنهای از پیش آموزش داده شده بر روی دیتاست ImageNet، لود میشود و سپس بر روی یک تصویر دلخواه عمل پیشبینی انجام میشود. در مثال بالا ما از تصویر یک نوع سگ (Pug) استفاده کردهایم که پیشبینی مدل برای کلاس این تصویر نیز همان Pug خواهد بود.
برای پیادهسازی مدل از پایه مراحل زیر را طی میکنیم. ابتدا مدل و بلوکهای مورد استفاده در آن را تعریف میکنیم:
اکنون نیاز است تا دیتاست مورد نظر خود را برای آموزش مدل آماده کنیم. ما در اینجا از دیتاست Cats vs. Dogs استفاده میکنیم.
اکنون مدل را ساخته و آن را کامپایل و train میکنیم. میتوانیم با model.summary() ساختار مدل ساخته شده را ببینیم. در اینجا دیتاست ما دو کلاس بیشتر ندارد پس k را برابر ۲ قرار میدهیم. ما با توجه به توضیحات مقاله از بهینهساز rmsprop استفاده کردهایم. همچنین از Early Stopping با patience سه استفاده شده است. طبق تنظیمات فوق آموزش مدل ما بعد از ۹ Epoch متوقف شد و به دقت نزدیک ۹۰ درصد رسید.
پس از آموزش مدل میتوانیم آن را ارزیابی کنیم. دقت مدل آموزش دیده ما بر روی دیتاست تست چیزی حدود ۸۹ درصد شد. همچنین برای تصویر تست دلخواه توانست به درستی کلاس آن را تشخیص دهد. شما میتوانید با دادن تصاویر دلخواه دیگر به مدل، خروجی آن را مشاهده کنید.
در بالا قطعه کدهای لازم برای پیادهسازی مدل MobileNet V2 از پایه و همچنین آموزش آن بر روی دیتاستی دلخواه آورده شد. میتوانید کدهای لازم برای پیادهسازی، آموزش و ارزیابی MobileNet V2 را به همراه وزنهای از پیش آموزش داده شده از گیت هاب دانلود کنید. ما برای پیادهسازی از فریمورک تنسورفلو استفاده کردیم اما میتوان این مدل را با فریمورکهای دیگری از جمله پایتورچ نیز پیادهسازی کرد. شما میتوانید پیادهسازی MobileNet V2 با پایتورچ به همراه تمامی کدهای فوق و نتیجه اجرای آنها را در این نوت بوک کولب مشاهده نمایید.
⏱︎ تاریخ نگارش: ۵ مرداد ۱۴۰۳
دیدگاهها