
بررسی MobileNet V3/V4
در این پست قصد داریم به بررسی مقالههای MobileNet V3 و MobileNet V4 بپردازیم.
ما در پستهای قبلی وبلاگ به بررسی مقالات MobileNet V1 و MobileNet V2 پرداختیم و آنها را پیادهسازی کردیم. در این پست از وبلاگ قصد داریم دو مدل جدیدتر از MobileNet یعنی نسخههای سوم و چهارم آن را بررسی کنیم.
MobileNet V3
در سال ۲۰۱۹ مقاله MobileNet V3 توسط محققینی از گوگل معرفی شد. MobileNet V3 از ایدههای مقالهها و روشهای قبلی استفاده کرده و با بهبود آنها سعی در ارائه شبکهای کاراتر دارد.
بلوک گلوگاه
در MobileNet V3 از ترکیب ساختار گلوگاهها با اتصالات معکوس موجود در MobileNet V2 و فشار و برانگیختگی (Squeeze and Excitation) موجود در MnasNet برای ارائه بلوکهای گلوگاه جدید استفاده میشود. ساختار این بلوکها در شکل ۱ نشان داده شده است.
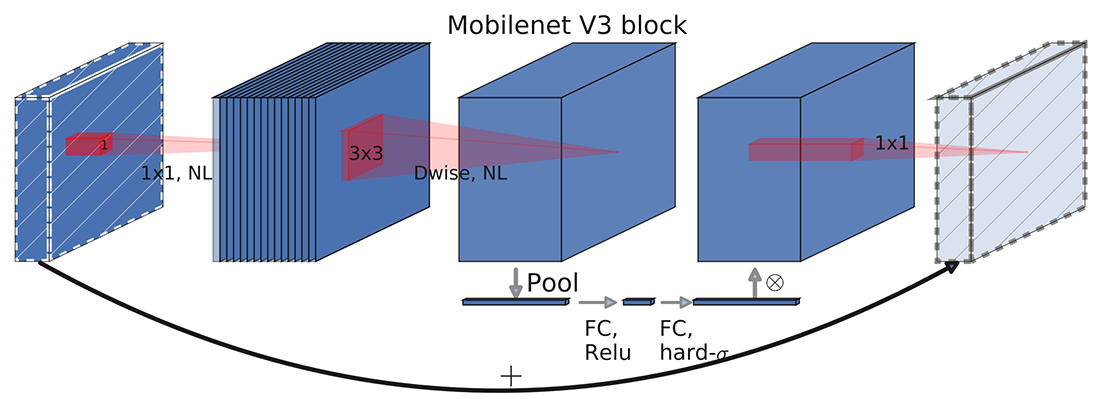
جستجوی معماری عصبی (NAS)
در MobileNet V3 از جستجوی معماری عصبی برای یافتن بهترین ساختار شبکه استفاده میشود و با استفاده از الگوریتم NetAdapt در هر لایه تعداد فیلترهای بهینه جستجو میشود. با استفاده از این تکنیکها میتوان مناسبترین شبکه ممکن را برای سختافزار هدف پیدا نمود.
تابع فعالساز جدید
با توجه به معرفی تابع فعالساز swish در مقالات اخیر و مشاهده افزایش دقت شبکه در اثر استفاده از آن، نویسندگان MobileNet V3 نیز به فکر استفاده از این تابع افتادند. اما این تابع برای پیادهسازی بر روی دستگاههای با منابع محدود مانند موبایل بهینه نبود، بنابراین در MobileNet V3 از تابع جدیدی به نام hard-swish استفاده میشود که نسخه قطعهای خطی از تابع swish میباشد. در محاسبه تابع swish از سیگموئید استفاده میشود که محاسبه آن بهینه نیست، ولی در تابع hard-swish پیشنهادی به جای سیگموئید از ReLU6 استفاده میشود که محاسبه آن بسیار سادهتر است. در شکل ۲ این دو تابع مقایسه شدهاند.
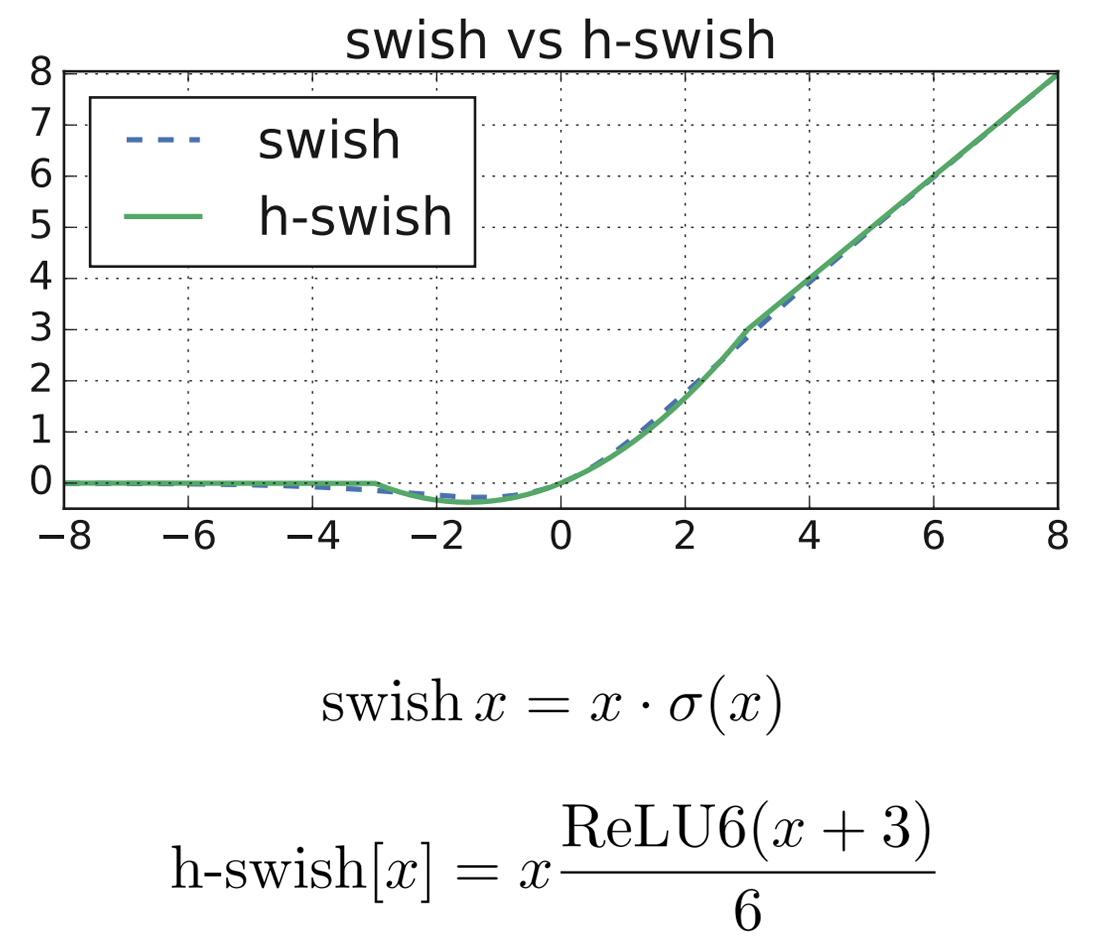
معماری MobileNet V3
مدل MobileNetV3 در دو نسخه Large و Small ارائه شده است. هر کدام از این دو مدل با توجه به میزان منابع در دسترس میتوانند مورد استفاده قرار بگیرند. ساختار این دو مدل در جدول ۱ آورده شده است.
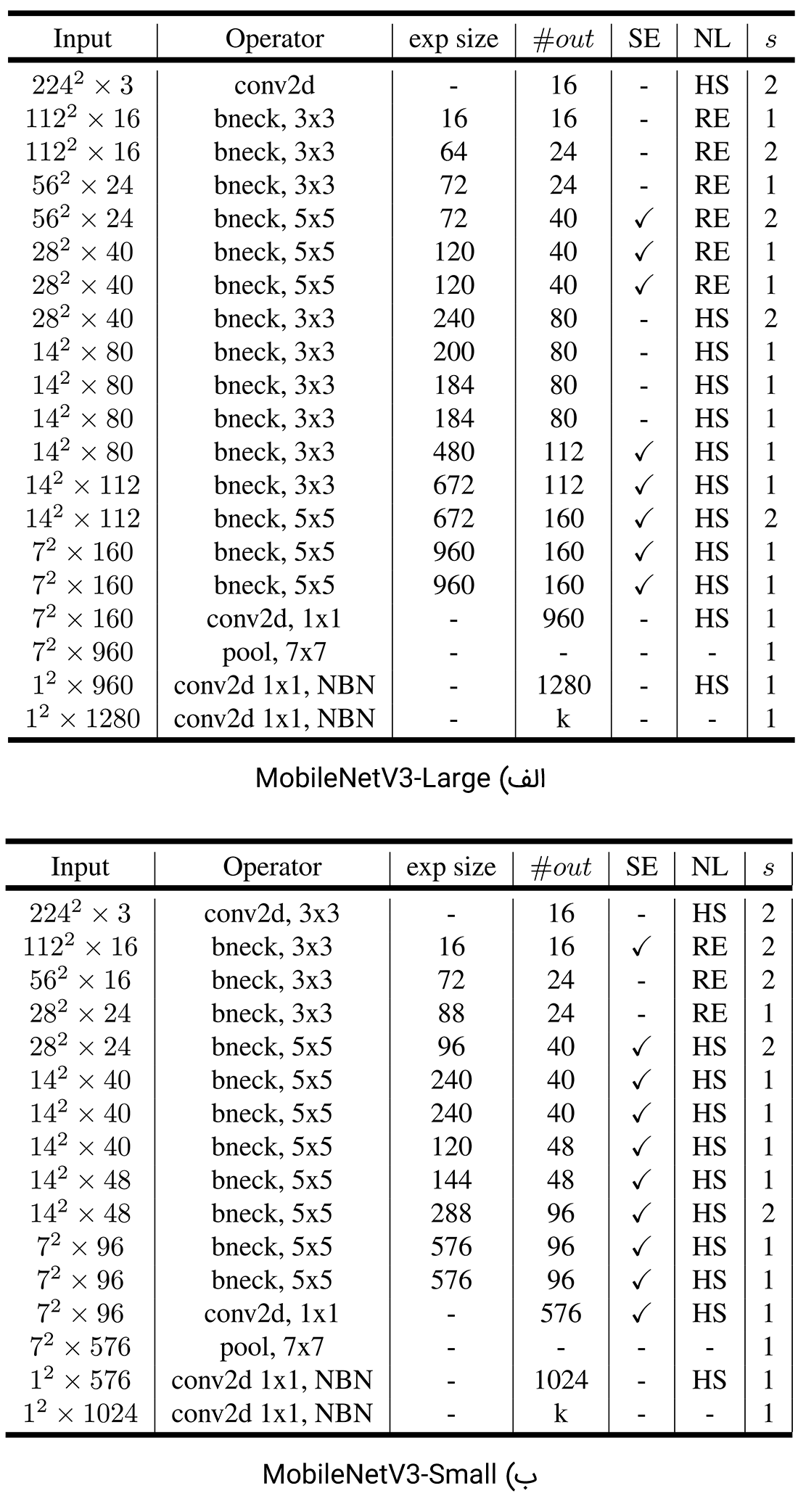
MobileNet V4
بار دیگر محققین گوگل در سال ۲۰۲۴ نسخه جدیدی از MobileNet را ارائه کردند. MobileNet V4 که آخرین نسخه MobileNet در هنگام نگارش این متن میباشد با استفاده از مجموعه تکنیکها و روشهای موجود در مقالات اخیر سعی در ارائه مدلی با بهترین عملکرد بر روی دستگاههای با منابع محدود از جمله موبایل دارد.
گلوگاههای سراسری (Universal Inverted Bottlenecks)
در MobileNet V4 از بلوک گلوگاه معکوس سراسری (UIB) استفاده میشود که یک بلوک سازگار برای طراحی کارآمد شبکه میباشد و در هنگام جستجوی معماری عصبی از افزایش بیش از حد پیچیدگی جلوگیری میکند. در واقع UIB نسخه توسعهیافته بلوک گلوگاه معکوس (IB) در MobileNet V2 میباشد. ساختار این بلوک در شکل ۳ نمایش داده شده است.
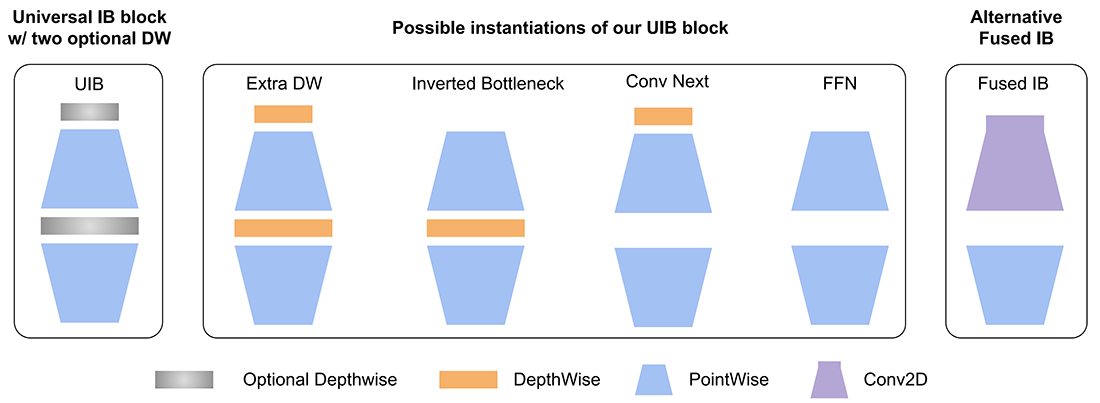
در ساختار UIB از دو فیلتر کانولوشنی عمقی (DW) اختیاری استفاده شده است، یکی قبل از لایه انبساط و دیگری بین لایه انبساط و لایه افکنش. وجود یا عدم وجود این DW ها بخشی از فرایند بهینهسازی NAS (جستجوی معماری عصبی) است که منجر به معماریهای جدید میشود. با وجود سادگی این ایده، بلوک جدید UIB به خوبی چند بلوک مهم موجود، از جمله بلوک IB موجود در MobileNetV2، بلوک ConvNext و بلوک FFN (فید فوروارد) در ViT را یکپارچه میکند. علاوه بر این، UIB یک نوع جدید از گلوگاه را معرفی میکند: بلوک ExtraDW که یک فیلتر کانولوشنی عمقی (DW) بیشتر نسبت به بلوک IB دارد.
توجه چند کوئری (Multi-Query Attention)
در MobileNet V4 از مکانیزم توجه موجود در ترانسفورمرها نیز استفاده میشود اما نه به صورت نسخه اصلی آن بلکه با تغییری کوچک در مکانیزم توجه که باعث افزایش ۳۹ درصدی سرعت استنتاج مدل میشود.
در مقاله MobileNet V4 عنوان میشود که در موبایلهای جدیدتر که از شتابدهندهها استفاده میکنند دیگر گلوگاه اصلی میزان پردازش مورد نیاز برای مدل نیست بلکه میزان دسترسی به حافظه است که اکنون مشکلساز است. بنابراین از ساختار جدیدی به نام توجه چند کوئری (MQA) به جای توجه چند سر (MHSA) استفاده میشود که نیاز به دسترسی به حافظه کمتری دارد. در MHSA کوئریها، کلیدها و مقادیر به فضاهای گوناگونی نگاشت میشوند تا جنبههای مختلف اطلاعات بدست آید. MQA این فرایند را با استفاده از کلیدها و مقادیر مشترک در همه سرها ساده میکند. در حالی که سرهای کوئری متعدد ضروری هستند، مدلهای بزرگ میتوانند به طور موثری یک سر را برای کلیدها و مقادیر به اشتراک بگذارند بدون اینکه دقت کاهش یابد. این امر باعث کاهش دسترسی به حافظه میشود، به خصوص در حالتی که سایز batch در مقایسه با ابعاد ویژگیها کوچکتر است. این حالت معمول برای مدلهای ویژن هیبریدی در برنامههای موبایل است که معمولا مکانیزم توجه در لایههای آخر این مدلها اعمال میشود. در این لایهها رزولوشن دادهها کم و ابعاد آنها زیاد است و همچنین معمولا سایز batch یک است.
استفاده از ماژولها و اپراتورهای ساده
در MobileNet V4 از ماژولهای ساده به جای المانهای پیچیده استفاده میشود. به طور مثال به جای توابع فعالساز پیچیده مانند GELU از تابع ساده ReLU استفاده میشود. به جای LayerNorm که به خوبی روی DSP (پردازندههای سیگنال دیجیتال) پشتیبانی نمیشود، از BatchNorm استفاده میشود. همچنین به دلیل کند بودن ساختار فشار و برانگیختگی (SE) روی شتابدهندهها از این ماژول در MobileNet V4 استفاده نمیشود.
جستجوی معماری عصبی (NAS)
در MobileNet V4 نیز از جستجوی معماری عصبی برای یافتن بهترین معماری ممکن برای سختافزار هدف استفاده میشود. همانطور که پیشتر نیز گفته شد ماژولهای UIB با استفاده از همین فرایند جستجو معماری عصبی ساختارشان شکل میگیرد و وجود یا عدم وجود DW ها در آنها مشخص میشود. در MobileNet V4 از یک جستجوی دو مرحلهای برای تعیین ساختار مدل استفاده میشود که منجر به بهبود کارایی مدل میشود.
تقطیر دانش (Knowledge Distillation)
MobileNet V4 با استفاده از تکنیک تقطیر دانش کارایی مدلهای خود را افزایش میدهد. برای مدل معلم از EfficientNet-L2 استفاده شده است. برای افزایش بیشتر کارایی نیز از تکنیک افزایش داده (Data augmentation) حین تقطیر دانش استفاده شده است. همچنین از دیتاست JFT برای افزایش بیشتر دادهها حین آموزش استفاده شده است.
معماری MobileNet V4
مدلهای MobileNet V4 در دو نسخه تماما کانولوشنی و هیبرید (کانولوشنی – ترانسفورمری) ارائه شدهاند. مدلهای کانولوشنی سه نسخه Small و Medium و Large دارند و مدلهای هیبریدی دو نسخه Medium و Large دارند. ساختار این مدلها در شکل ۴ نشان داده شده است.





شکل ۴: معماری MobileNet V4 (ورق بزنید)
در این پست به بررسی دو نسخه آخر یکی از محبوبترین مدلهای سبک وزن برای اجرا بر روی دستگاههای موبایل یعنی MobileNet پرداختیم و ویژگیها و ساختار آنها را بررسی کردیم. با توجه به اینکه این مدلها توسط محققان گوگل توسعه یافته است میتوان به راحتی از آنها در فریمورک تنسورفلو استفاده کرد و پیادهسازی این مدلها به صورت آماده در تنسورفلو موجود است. شما میتوانید نگاهی به کد آماده این مدلها در صفحه رسمی تنسورفلو در گیتهاب بیندازید.
⏱︎ تاریخ نگارش: ۱۲ مرداد ۱۴۰۳
دیدگاهها