
بررسی و پیادهسازی EfficientNet
در این پست قصد داریم به بررسی و پیادهسازی مقاله EfficientNet بپردازیم.
شبکههای عصبی کانولوشنی معمولا با توجه به یک مقدار منابع در دسترس خاص طراحی میشوند و سپس در صورت وجود منابع بیشتر، برای دقت بیشتر مقیاسبندی میشوند. در مقاله EfficientNet، به طور سیستماتیک مقیاسبندی مدل بررسی شده و تشخیص داده میشود که متعادل کردن دقیق عمق، عرض و وضوح شبکه میتواند به عملکرد بهتر منجر شود. همچنین نویسندگان مقاله با استفاده از جستجوی معماری عصبی یک شبکه پایه را طراحی کرده و در سایزهای بزرگتر مقیاسبندی میکنند تا مجموعهای از مدلهای کارآمد به نام EfficientNets را بدست آورند. این مدلها نسبت به مدلهای کانولوشنی قبلی دقت و عملکرد بسیار بهتری دارند.
مقیاسبندی ترکیبی مدل
تا قبل از EfficientNet روشهایی که به مقیاسبندی مدل میپرداختند، شبکه را فقط در یکی از مقیاسهای عمق، عرض یا اندازه تصویر ورودی (وضوح) گشترش میدادند. در EfficientNet با انجام آزمایشهای متعدد نشان داده شد که افزایش مقیاس به طور همزمان (در عمق، عرض و ارتفاع) باعث افزایش دقت و کارایی شبکه میشود (شکل ۱). به طور شهودی نیز روش مقیاسبندی ترکیبی منطقی است زیرا اگر تصویر ورودی بزرگتر باشد، شبکه به لایههای بیشتری برای افزایش میدان دریافت (receptive field) و کانالهای بیشتری برای ثبت الگوهای ریزدانهتر روی تصویر بزرگتر نیاز دارد.
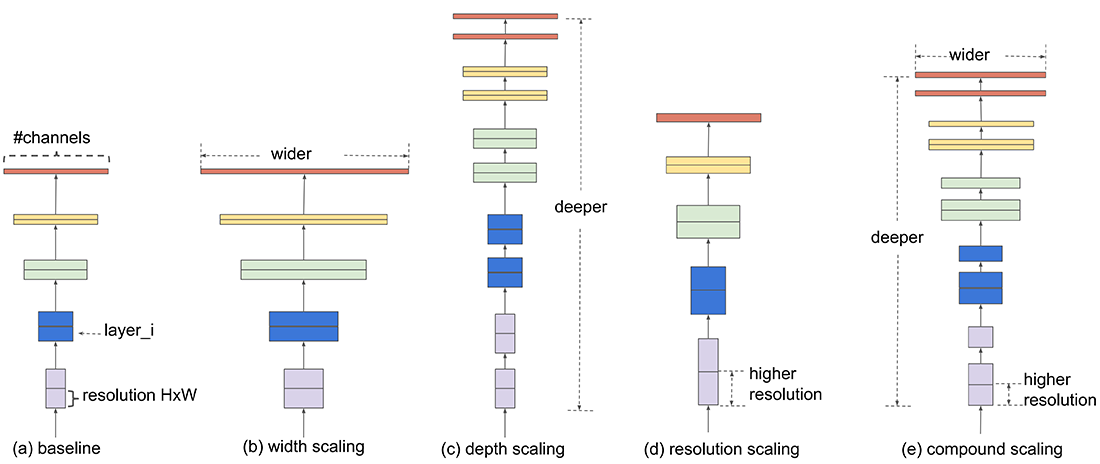
اگرچه میتوان به صورت دلخواه به طور همزمان دو یا سه مقیاس فوق را افزایش داد اما تنظیم این مقیاسها به صورت دستی بسیار سخت و خسته کننده است و علاوه بر این ممکن است بهینه نباشد. در مقاله EfficientNet نشان داده شد که میتوان این افزایش مقیاس چندگانه را با استفاده از یک نسبت ثابت انجام داد. به طور مثال اگر قصد داریم تا از 2N منابع بیشتر استفاده کنیم، آنگاه به سادگی میتوان عمق شبکه را با αN، عرض شبکه را با βN و رزولوشن را با γN افزایش داد که α و β و γ ضرایب ثابتی هستند که با یک جستجوی کوچک شبکهای روی مدل کوچک اصلی تعیین میشوند.
به طور دقیقتر در این مقاله از فرمول زیر (فرمول ۱) برای مقیاسبندی مدل استفاده میشود:
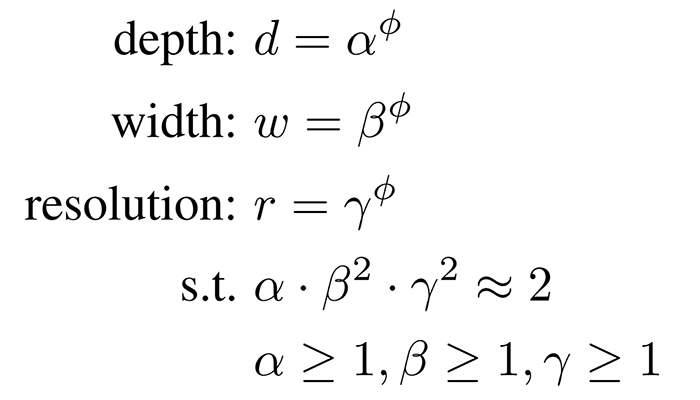
به طور شهودی، φ یک ضریب مشخص شده توسط کاربر است که مقدار منابع بیشتر برای مقیاسبندی مدل را کنترل میکند، در حالی که α و β و γ نحوه اختصاص این منابع اضافی را به ترتیب به عرض، عمق و وضوح شبکه مشخص میکنند.
قابل توجه است که FLOPS یک عملیات کانولوشن معمولی متناسب با d و w2 و r2 است، یعنی دو برابر کردن عمق شبکه، FLOPS را دو برابر میکند، اما دو برابر کردن عرض یا وضوح شبکه، FLOPS را چهار برابر افزایش میدهد. از آنجایی که معمولا در شبکههای CNN عملیات کانولوشنی بر سایر هزینههای محاسباتی غالب است، مقیاسبندی یک مدل کانولوشنی با فرمول ۱ تقریباً کل FLOPS را با نسبت (α · β2 · γ2)φ افزایش میدهد. در این مقاله α · β2 · γ2 ≈ 2 در نظر گرفته میشود تا برای هر φ جدیدی، مقدار کل FLOPS تقریبا به مقدار 2φ افزایش یابد.
معماری EfficientNet
همانطور که گفته شد در این مقاله از جستجوی معماری عصبی برای یافتن بهترین معماری ممکن استفاده میشود. با توجه به گفته نویسندگان مقاله، برای جستجوی معماری عصبی از پارادایمی مشابه MnasNet استفاده میشود و شبکه بدست آمده را EfficientNet-B0 مینامند. جدول ۱ معماری EfficientNet-B0 را نشان میدهد.
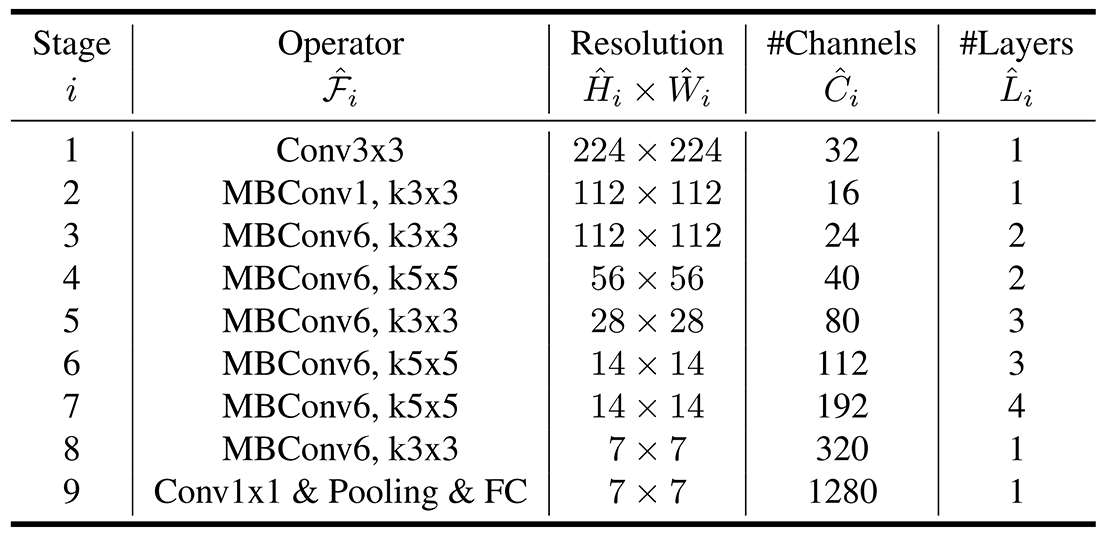
همانگونه که مشاهده میشود بلوک اصلی سازنده EfficientNet-B0 گلوگاه کانولوشنی موجود در MobileNetV2 یا همان MBConv میباشد. همچنین به گفته نویسندگان از فشار و برانگیختگی نیز استفاده شده است.
نویسندگان مقاله با شروع از شبکه پایه EfficientNet-B0، با استفاده از روش مقیاسبندی ترکیبی ارائه شده، شش شبکه بزرگتر (B1 تا B7) را نیز ارائه میکنند. روش کار بدینگونه است:
- در مرحله اول φ = 1 ثابت میشود و یک جستجو شبکهای کوچک برای یافتن α و β و γ بهینه انجام میشود. به طور خاص بهترین مقادیر یافت شده روی EfficientNet-B0 برابر α = 1.2 و β =1.1 و γ = 1.15 میباشند.
- در مرحله دوم α و β و γ ثابت میشوند و شبکه پایه (B0) با مقادیر مختلف φ و با استفاده از فرمول ۱ افزایش مقیاس مییابد تا شبکههای B1 تا B7 بدست آیند.
پیادهسازی
پیادهسازی آماده مدل EfficientNet هم در فریمورک تنسورفلو و هم پایتورچ موجود است. برای استفاده از این مدل آماده و از پیش آموزش داده شده تنها نیاز است تا از دستورات زیر استفاده نمایید.
کد تنسور فلو
کد پایتورچ
در قطعه کدهای بالا ابتدا مدل EfficientNet با وزنهای از پیش آموزش داده شده بر روی دیتاست ImageNet، لود میشود و سپس بر روی یک تصویر دلخواه عمل پیشبینی انجام میشود. در مثال بالا ما از تصویر یک نوع سگ (Pug) استفاده کردهایم که پیشبینی مدل برای کلاس این تصویر نیز همان Pug خواهد بود.
پیادهسازی از پایه با استفاده از پایتورچ
در این قسمت قصد داریم مدل EfficientNet را از پایه پیادهسازی کرده و نسخه B0 آن را بر روی دیتاست Oxford-IIIT Pet آموزش دهیم. ابتدا کتابخانههای مورد نیاز را افزوده و ابرپارامترهای ضروری برای بلوک MBConv را طبق جدول ۱ تعریف میکنیم. علاوه بر این، ابرپارامترهای مورد نیاز برای ساخت نسخههای مقیاس یافته بر اساس ضریب φ را پیکربندی میکنیم. هر نسخه به صراحت با وضوح تصویر ورودی و مقادیر Dropout مرتبط تعریف شده است.
سپس دو ماژول ConvBlock و SqueezeExcitation را تعریف میکنیم که توسط سایر ماژولها استفاده خواهند شد.
اکنون کلاس MBBlock را تعریف میکنیم که در اصل همان بلوک MBConv موجود در MobileNetV2 به همراه مکانیزم فشار و برانگیختگی (Squeeze & Excitation) میباشد.
اکنون کلاس EfficientNet را تعریف میکنیم که تعریفکننده ساختار مدل EfficientNet میباشد.
اکنون که مدل EfficientNet تعریف شد قصد داریم به آموزش آن بر روی دیتاست Oxford-IIIT Pet بپردازیم. برای این کار توابع و کلاسهای مورد نیاز برای آموزش مدل تعریف میشود. ما از Early Stopping و تعداد Epoch برابر ۵۰ استفاده میکنیم. البته در آزمایشهای ما معلوم شد این تعداد Epoch برای آموزش مدل کافی نیست و برای رسیدن به دقت مناسب به تعداد Epoch های بسیار بیشتری برای آموزش مدل نیاز است که ما دیگر به افزایش آن نپرداختیم اما شما میتوانید طبق نیاز خود این عدد را افزایش دهید. همچنین همانطور که گفته شد ما در اینجا از نسخه EfficientNet-B0 استفاده میکنیم که سبکترین نسخه EfficientNet میباشد. تعداد کلاسهای دیتاست ما ۳۷ عدد میباشد که آن را نیز در متغیر num_classes تنظیم کردهایم. همچنین از بهینهساز Adam و تابع خطا CrossEntropy استفاده کردهایم.
در نهایت نیز مدل را بر روی یک تصویر تست ارزیابی کرده و خروجی را نمایش میدهیم.
در بالا قطعه کدهای لازم برای پیادهسازی مدل EfficientNet از پایه و همچنین آموزش آن بر روی دیتاستی دلخواه آورده شد. شما میتوانید کدهای لازم برای پیادهسازی، آموزش و ارزیابی EfficientNet را به همراه وزنهای از پیش آموزش داده شده از گیتهاب دانلود کنید. همچنین میتوانید تمامی کدهای فوق به همراه نتیجه اجرای آنها را در این نوتبوک کولب مشاهده نمایید. همچنین لازم به ذکر است که ما در پیادهسازی کدهای فوق از این پست در Medium کمک گرفتیم.
⏱︎ تاریخ نگارش: ۲۸ مرداد ۱۴۰۳
دیدگاهها