
بررسی GhostNet V2/V3
در این پست قصد داریم به بررسی مقالههای GhostNetV2 و GhostNetV3 بپردازیم.
ما در پست قبلی وبلاگ به بررسی مقاله GhostNet پرداختیم و آن را پیادهسازی کردیم. در این پست از وبلاگ قصد داریم دو مدل جدیدتر از GhostNet یعنی نسخههای دوم و سوم آن را بررسی کنیم.
GhostNetV2
نسخه دوم GhostNet در سال ۲۰۲۲ توسط محققان شرکت هواوی با عنوان GhostNetV2: Enhance Cheap Operation with Long-Range Attention منتشر شد.
ایده اصلی GhostNetV2 استفاده از مکانیزم توجه (attention) برای افزایش دقت شبکه و پردازش ویژگیها به صورت سراسری میباشد. البته با توجه به اینکه مکانیزم توجه در حالت کلی باعث افت سرعت و افزایش بار محاسباتی شبکه میشود، نویسندگان مقاله از مکانیزمی ابداعی به نام DFC به جای مکانیزم توجه عادی استفاده کردهاند که بار محاسباتی کمتر و سرعت بیشتری دارد. آنها با استفاده از این مکانیزم جدید اقدام به ارائه شبکه GhostNetV2 کردهاند که در ادامه آن را بررسی خواهیم کرد.
مکانیزم DFC
اگرچه مکانیزم توجه میتواند وابستگیهای سراسری را به خوبی مدلسازی کند، اما برای پیادهسازی بهینه نیست. در مقایسه با آن، لایههای تماما متصل (FC) با وزنهای ثابت برای پیادهسازی سادهتر و آسانتر هستند و میتوان از آنها به جای مکانیزم توجه برای تولید نقشههای ویژگی سراسری نیز استفاده کرد. با این حال پیچیدگی زمانی پردازش لایههای FC نیز از نوع درجه دو (quadratic) میباشد و با افزایش سایز ویژگی افزایش مییابد. واضح است که این مورد در سناریوهای واقعی غیر قابل قبول است زیرا اغلب رزولوشن تصویر ورودی بزرگ میباشد و باعث افزایش پیچیدگی محاسباتی شبکه میگردد.
برای حل این مشکل و با توجه به اینکه ویژگیهای تصویر به صورت ذاتی به صورت دو بعدی هستند، نویسندگان مقاله پیشنهاد تجزیه FC به دو مرحله افقی و عمودی را میدهند که باعث کاهش بار محاسباتی لایههای FC میشود. آنها این مکانیزم را decoupled fully connected یا DFC مینامند. این مکانیزم در شکل ۱ نشان داده شده است.
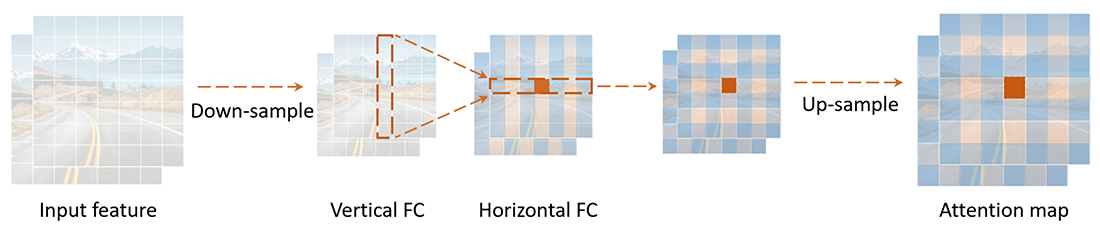
گلوگاه Ghost بهبود یافته
همانطور که در بالا توضیح داده شد، در GhostNetV2 علاوه بر ویژگیهای محلی، ویژگیهای سراسری نیز با استفاده از مکانیزم DFC استخراج شده و مورد استفاده قرار میگیرند. این مکانیزم در گلوگاه Ghost به صورت شکل ۲ افروده شده است.
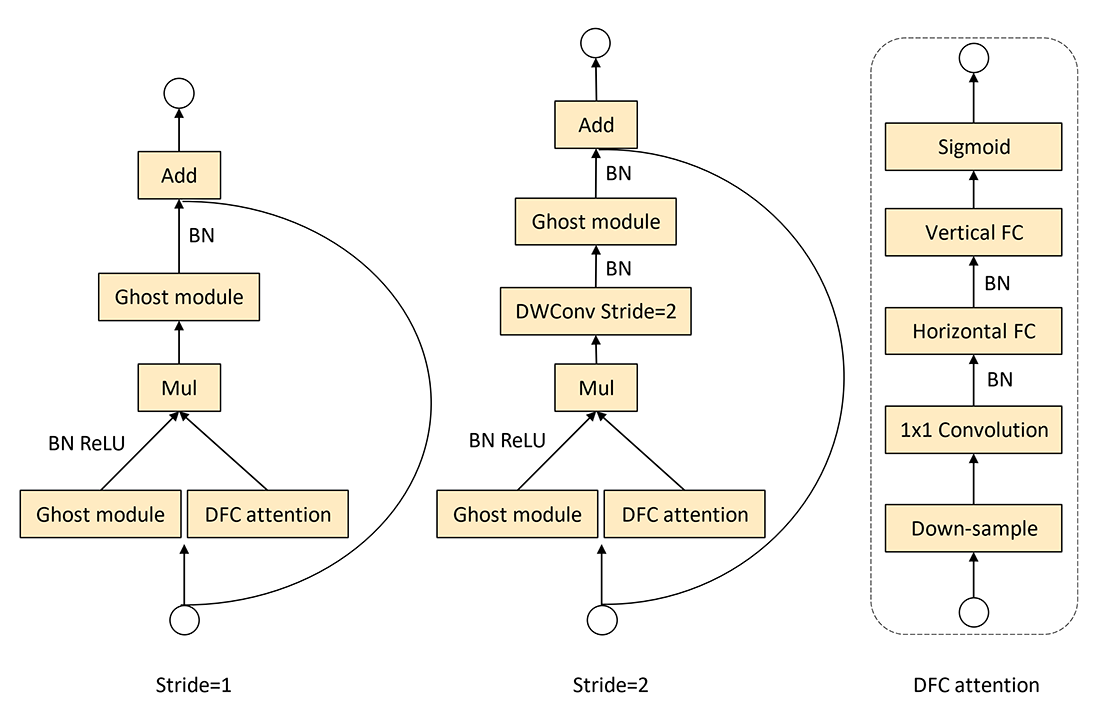
از آنجایی که ماژول Ghost یک عملیات کم هزینه و کارآمد است، اعمال مکانیزم DFC به طور موازی با آن هزینه محاسباتی اضافی را به همراه خواهد داشت. از این رو قبل از اعمال هر گونه عملیاتی در DFC اندازه ویژگیها کاهش مییابد (عملیات Down-sample در سمت راست شکل ۲). در عملیات down-sample بهطور پیشفرض، عرض و ارتفاع هر دو به نصف طول اصلی خود کوچک میشوند، که باعث کاهش ۷۵ درصدی FLOP در DFC میشود. سپس اندازه نقشه ویژگی تولید شده به اندازه اصلی افزایش مییابد تا با اندازه ویژگی در شاخه ماژول Ghost مطابقت داشته باشد. البته عملیات افزایش سایز بعد از اعمال تابع Sigmoid انجام میشود تا سرعت پردازش افزایش یابد. در عمل برای down-sample از average pooling و برای up-sample از bilinear interpolation استفاده میشود.
فرآیند تجمیع اطلاعات دو شاخه ماژول Ghost و DFC در شکل ۳ نشان داده شده است. با ورودی یکسان، ماژول Ghost و DFC دو شاخه موازی هستند که اطلاعات را از دیدگاههای مختلف استخراج میکنند. خروجی حاصل ضرب عنصر به عنصر آنها است که حاوی اطلاعاتی از ویژگیهای ماژول Ghost و ماژول DFC میباشد.
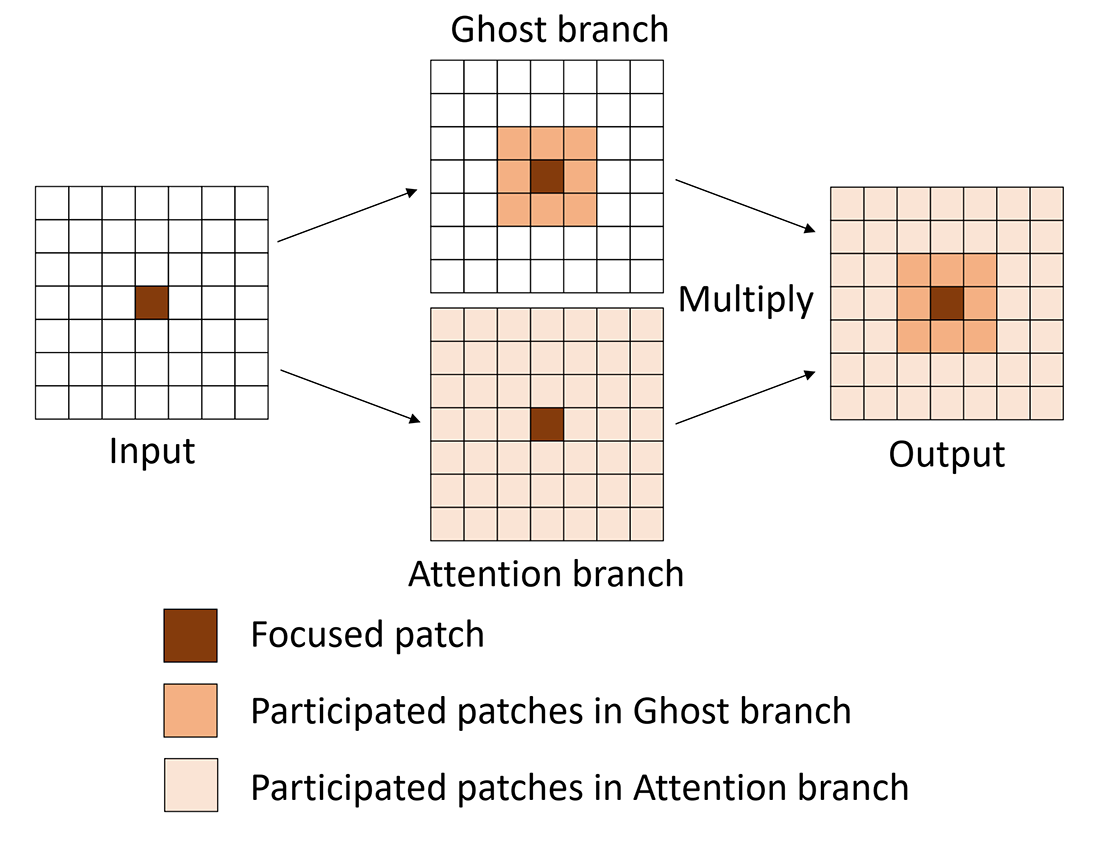
معماری
معماری کلی شبکه GhostNetV2 نیز شبیه نسخه اول آن میباشد، با این تفاوت که در آن به جای استفاده از گلوگاه Ghost معمولی از گلوگاه Ghost بهبود یافته استفاده شده است. شما میتوانید کدهای مربوط به پیادهسازی GhostNetV2 را در ریپازیتوری رسمی آن در گیتهاب مشاهده نمایید.
GhostNetV3
نسخه سوم GhostNet در سال ۲۰۲۴ توسط محققان شرکت هواوی با عنوان GhostNetV3: Exploring the Training Strategies for Compact Models منتشر شد و همانطور که از نام آن پیداست، این مقاله به جای ارائه معماری جدید، به بررسی استراتژیهای مختلف برای آموزش شبکههای فشرده و سبکوزن میپردازد. نویسندگان مقاله بر اهمیت استراتژیهایی مانند پارامترسازی مجدد و تقطیر دانش در آموزش شبکههای سبکوزن تاکید میکنند و در عین حال استفاده از بعضی تکنیکهای افزایش داده مانند Mixup و CutMix را غیر ضروری و حتی نامناسب برای عملکرد مدل معرفی میکنند. تمامی این موارد طبق آزمایشهای مختلف بررسی و تایید شده است.
پارامترسازی مجدد (Re-parameterization)
با موفقیت پارامترسازی مجدد در شبکههای کانولوشنی معمولی، نویسندگان GhostNetV3 به فکر استفاده از این استراتژی برای بهبود عملکرد مدل افتادهاند. این کار با افزودن شاخههای تکراری به لایههای کانولوشنی انجام میشود که هر کدام با batch normalization نیز دنبال شدهاند. طرح ارائه شده برای پارامترسازی مجدد GhostNetV3 در شکل ۴ ارائه شده است.
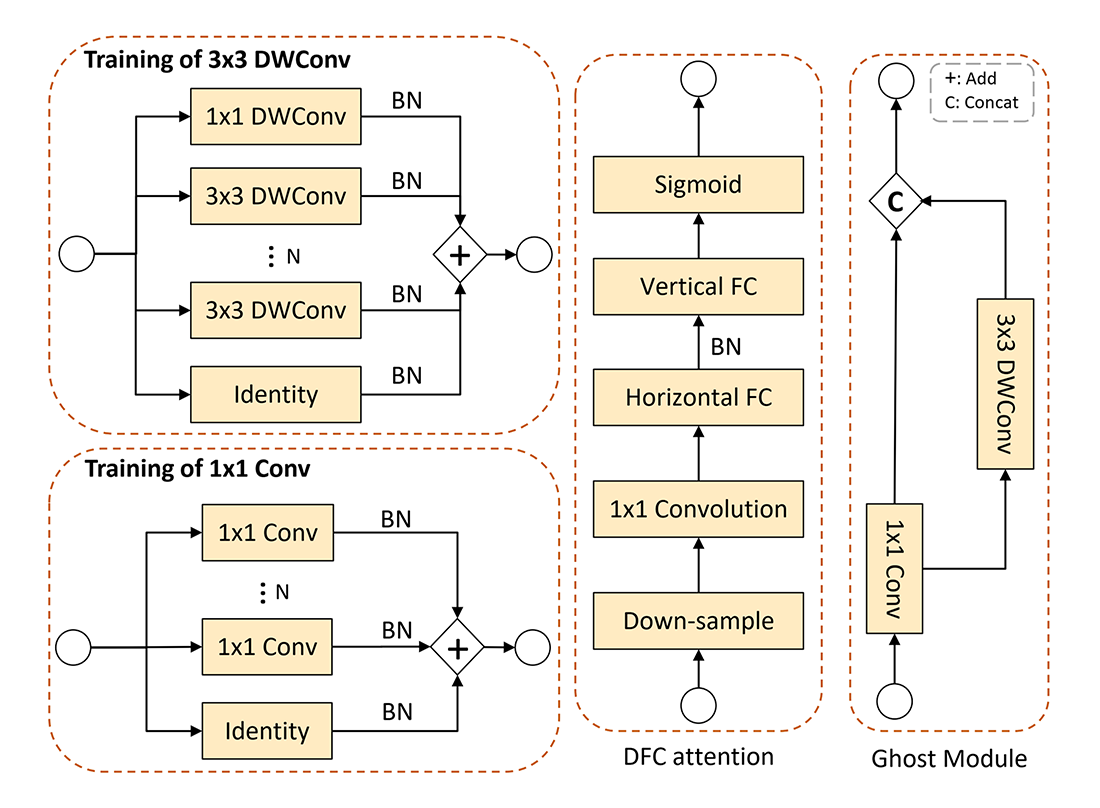
همانطور که در شکل ۴ پیداست، برای آموزش لایههای کانولوشنی 3×3 یک شاخه کانولوشن 1×1 نیز اضافه شده است. طبق نتایج آزمایشات بدست آمده این کار باعث بهبود عملکرد مدل میشود. همچنین طبق آزمایشیات انجام شده مقدار بهینه برای تعداد شاخهها برابر N=3 اعلام شده است.
در زمان استنتاج (اجرای مدل)، شاخههای تکراری را میتوان از طریق فرآیند پارامترسازی معکوس حذف کرد.
تقطیر دانش (Knowledge distillation)
تقطیر دانش یک روش فشردهسازی مدل است که که در آن پیش بینیهای یک مدل معلم بزرگ از قبل آموزشدیده به عنوان هدف یادگیری یک مدل دانشآموز کوچک در نظر گرفته میشود. فرض کنید نمونه x با برچسب y موجود است. اگر احتمالات پیشبینی شده توسط مدل معلم و دانشآموز را به ترتیب با Γt(x) و Γs(x) نشان دهیم، تابع ضرر کلی در تقطیر دانش را میتوان به صورت زیر فرموله کرد:
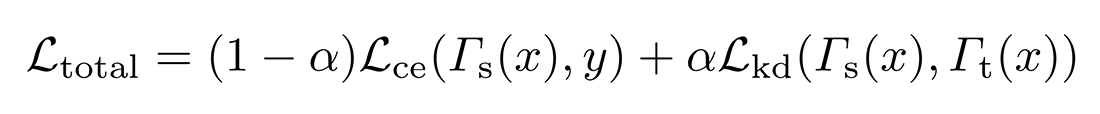
که در آن α یک فراپارامتر متعادلسازی، Lce نشاندهنده تابع خطا cross-entropy و Lkd نشاندهنده تابع خطا تقطیر دانش است که معمولا از تابع واگرایی Kullback-Leibler برای محاسبه آن استفاده میشود:
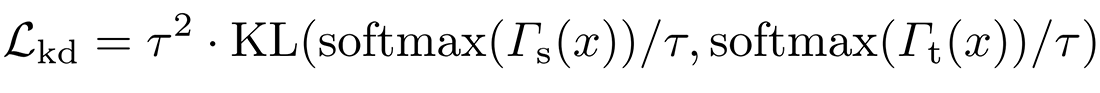
که در آن τ یک ابرپارامتر برای smoothing برچسب به نام پارامتر دما است. در آزمایشات مقدار بهینه برای α و τ به ترتیب برابر 0.5 و 1 بدست آمده است.
برنامه یادگیری (Learning schedule)
نرخ یادگیری یک پارامتر حیاتی در بهینهسازی شبکههای عصبی است. معمولا دو نوع نرخ یادگیری مورد استفاده قرار می گیرد: step و cosine. نرخ یادگیری step سرعت یادگیری را به صورت خطی کاهش میدهد، در حالی که نرخ یادگیری cosine سرعت یادگیری را در ابتدا به آرامی کاهش میدهد، در وسط تقریباً خطی میشود و در پایان دوباره سرعتش کاهش مییابد. طبق آزمایشات انجام شده مشخص شده است که برای مدلهای فشرده، نرخ یادگیری cosine منجر به نتایج بهتر میگردد.
میانگین متحرک نمایی (Exponential moving average) یا به اختصار EMA، اخیراً به عنوان یک رویکرد مؤثر برای بهبود دقت اعتبارسنجی و افزایش استحکام مدلها ظاهر شده است. به طور خاص، EMA به تدریج پارامترهای یک مدل را در طول زمان آموزش میانگینگیری میکند. فرض کنید پارامترهای مدل در گام t ام، Wt باشد، EMA مدل به صورت زیر محاسبه میشود:
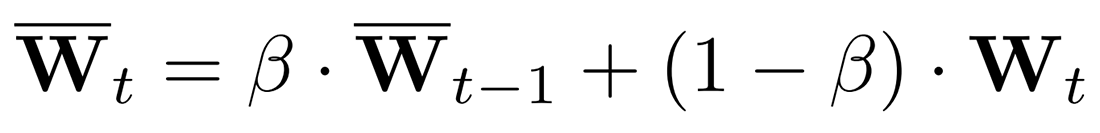
که β یک ابرپارامتر است و مقدار بهینه برای آن طبق آزمایشات برابر 0.9999 بدست آمده است.
افزایش داده (Data augmentation)
طبق آزمایشات انجام شده، دو تکنیک random augmentation و random erasing به عنوان تکنیکهای موثر افزایش داده برای بهبود دقت مدلهای فشرده معرفی شدهاند. در مقابل طبق آزمایشات دو تکنیک Mixup و CutMix نتایج موثری نداشتهاند و حتی باعث کاهش دقت مدل گردیدهاند.
روش random augmentation یک رویکرد افزایش داده تصادفی را پیشنهاد میکند که در آن همه استراتژیهای فرعی با احتمال یکسان انتخاب میشوند. این در مقابل روشی به نام auto augmentation میباشد. در auto augmentation از ۲۵ ترکیب استراتژی فرعی استفاده میشود که هر کدام شامل دو تبدیل هستند. برای هر تصویر ورودی، یک ترکیب از استراتژیهای فرعی به طور تصادفی انتخاب میشود و تصمیم در مورد اعمال هر تبدیل در استراتژی فرعی با احتمال معینی تعیین میشود.
روش random erasing به طور تصادفی یک منطقه مستطیلی را در تصویر انتخاب میکند و پیکسلهای آن را با مقادیر تصادفی جایگزین میکند. روشهای ترکیب تصویر مانند Mixup و CutMix دو تصویر را برای ایجاد یک تصویر جدید ترکیب میکنند. به طور خاص، Mixup یک شبکه عصبی را بر روی ترکیبات محدب از جفت تصاویر و برچسبهای آنها آموزش میدهد، در حالیکه CutMix به طور تصادفی یک منطقه را از یک تصویر حذف میکند و ناحیه مربوطه را با یک پچ از تصویر دیگر جایگزین میکند.
معماری
معماری کلی شبکه GhostNetV3 نیز شبیه نسخههای قبلی میباشد و در این نسخه صرفا به استفاده از تکنیکهای مختلف برای آموزش بهتر شبکه روی آورده شده است. شما میتوانید کدهای مربوط به پیادهسازی GhostNetV3 را در ریپازیتوری رسمی آن در گیتهاب مشاهده نمایید.
⏱︎ تاریخ نگارش: ۲۲ مهر ۱۴۰۳
دیدگاهها