
بررسی مقاله EdgeViT
در این پست مقاله EdgeViT را بررسی میکنیم و با ایدههای مطرح شده در آن آشنا میشویم.
در سال ۲۰۲۲ مقالهای تحت عنوان EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers ارائه شد که به دنبال یافتن مدلی سبک وزن مبتنی بر ترانسفورمرها برای کار با تصاویر بود. در این مقاله با ارائه ایدههایی همچون گلوگاه تبادل اطلاعات محلی-سراسری-محلی (LGL) و توجه پراکنده (Sparse Attention) مدلی ترکیبی (کانولوشنی-ترانسفورمری) و سبک وزن ارائه میشود که توانایی اجرا بر روی دستگاههای با منابع محدود را داراست و در عین دستیابی به دقت مناسب، مصرف انرژی و تاخیر کمی دارد.
گلوگاه محلی-سراسری-محلی (Local-Global-Local bottleneck)
مکانیزم توجه برای یادگیری ویژگیهای سراسری و وابستگیهای فضایی دوربرد در تصویر، که برای تشخیص بصری حیاتی است، بسیار مؤثر است. از سوی دیگر، از آنجایی که تصاویر دارای افزونگی فضایی بالایی هستند (به عنوان مثال، پچهای نزدیک به هم از نظر معنایی مشابه هستند)، اعمال مکانیزم توجه بر روی همه توکنها، حتی در یک نقشه ویژگی با رزولوشن کم، ناکارآمد است. برخلاف سایر بلوکهای ترانسفورمری که در هر مکان فضایی (توکن) مکانیزم توجه را اعمال میکنند، گلوگاه محلی-سراسری-محلی (LGL) ارائه شده در این مقاله فقط مکانیزم توجه را برای زیرمجموعهای از توکنها محاسبه میکند. البته LGL همچنان تعاملات فضایی کامل را، همانطور که در مکانیزم توجه استاندارد (MHSA) وجود دارد، ممکن میسازد.
برای رسیدن به این هدف، مکانیزم توجه به ماژولهای متوالی تجزیه میشود که توکنها را در محدودههای مختلف پردازش میکنند. این امر در شکل ۱ قسمت (b) نشان داده شده است.
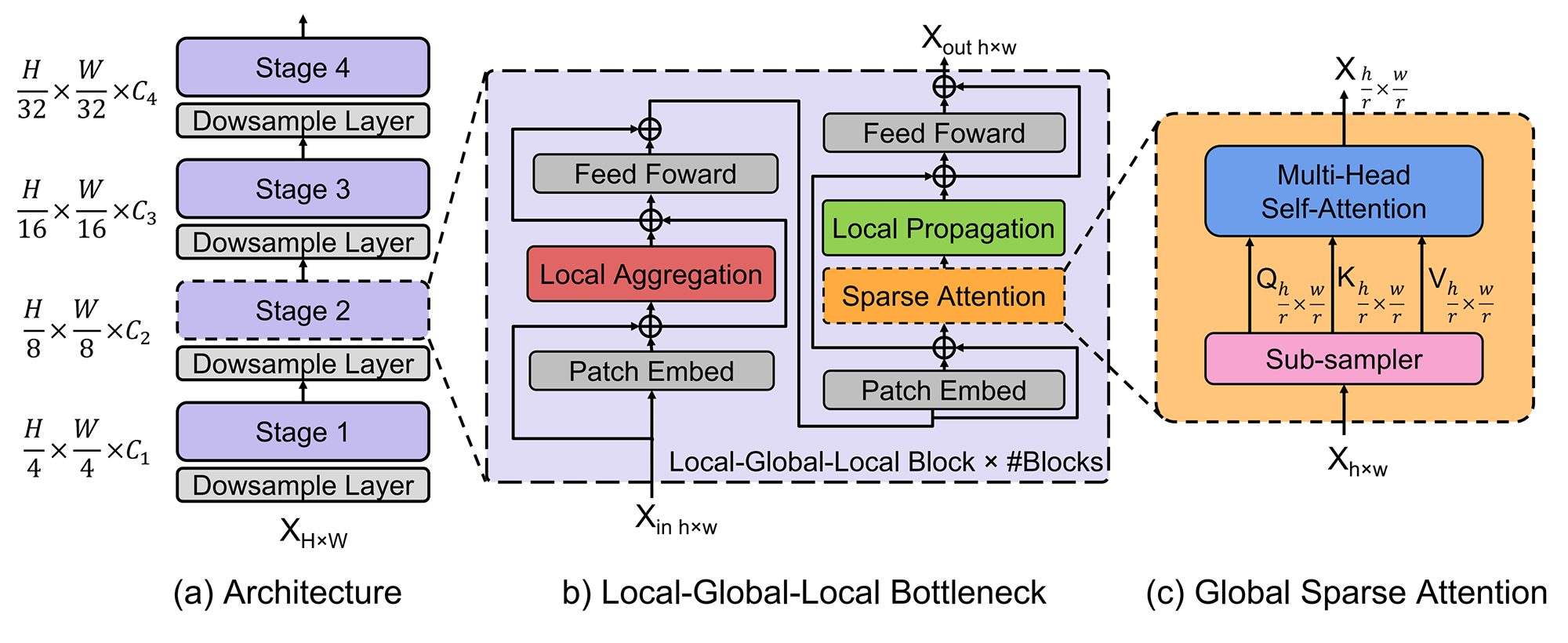
سه عملیات کارآمد در LGL وجود دارد: i) تجمیع محلی (Local aggregation) که اطلاعات را فقط از توکنهای نزدیک محلی جمع آوری میکند. ii) توجه پراکنده سراسری (Global sparse attention) که روابط دوربرد را بین مجموعهای از توکنهای نماینده مدل میکند که در آن هر یک از آنها به عنوان نماینده یک پنجره محلی در نظر گرفته میشوند. iii) انتشار محلی (Local propagation) که اطلاعات زمینهای سراسری را که توسط نمایندگان یاد گرفته شده است به توکنهای غیر نماینده در همان پنجره منتشر میکند. با ترکیب این موارد، گلوگاه LGL تبادل اطلاعات بین هر جفت توکن را با هزینه محاسباتی کم امکانپذیر میکند.
در شکل ۲ این سه عملیات با ذکر یک مثال به وضوح نشان داده شدهاند.
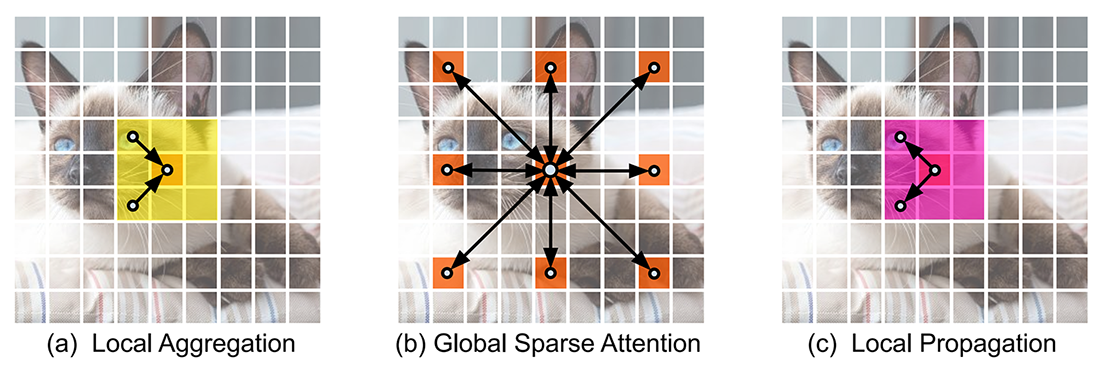
در زیر هر یک از این سه عملیات به تفصیل توضیح داده شده است:
- تجمیع محلی (Local aggregation): برای هر توکن، از کانولوشنهای عمقی و نقطهای برای جمع آوری اطلاعات در پنجرههای محلی با اندازه k×k استفاده میشود (شکل ۲(a)).
- توجه پراکنده سراسری (Global sparse attention): مجموعه پراکندهای از توکنهای نماینده که به طور یکنواخت در سرتاسر فضا توزیع شدهاند، به صورت یک توکن برای هر پنجره r×r نمونه برداری میشود. در اینجا r نشاندهنده نرخ نمونه برداری است. سپس مکانیزم توجه فقط روی این توکنهای انتخاب شده اعمال میشود (شکل ۲(b)). این متمایز از تمام ViT های موجود است که در آن همه توکنها در محاسبه مکانیزم توجه درگیر هستند.
- انتشار محلی (Local propagation): اطلاعات زمینهای سراسری کدگذاری شده در توکنهای نماینده، توسط ترانهاده کانولوشن به توکنهای همسایه منتشر میشود (شکل ۲(c)).
معماری
در مقاله خانوادهای از EdgeViT ها با پیچیدگیهای محاسباتی مختلف (یعنی 0.5G، 1G و 2G) ارائه شده است. پیکربندی این مدلها در جدول ۱ آورده شده است.

همانند ViT های سلسله مراتبی، EdgeViT از چهار مرحله (stage) تشکیل شده است که در آنها به تدریج، وضوح فضایی (یعنی طول دنباله توکن) کاهش و تعداد کانالها افزایش مییابد. برای کاهش وضوح در هر stage، از یک لایه کانولوشن با هسته 2×2 و گام ۲ استفاده میشود، به استثنای مرحله اول که ورودی با فیلتر 4×4 و گام ۴ کاهش وضوح مییابد.
همچنین از conditional positional encoding به جای absolute positional encoding استفاده میشود زیرا عملکرد بهتری دارد. این عملیات را می توان با استفاده از کانولوشن عمقی دو بعدی با اتصال میانبر پیادهسازی کرد. این عملیات قبل از تجمیع محلی و توجه پراکنده سراسری قرار می گیرد.
شبکه فید فوروارد (FFN) از دو لایه خطی تماما متصل تشکیل شده است که تابع GeLU در بین آنها قرار گرفته است. توجه پراکنده سراسری از یک نمونهبردار یکنواخت فضایی با نرخ نمونهبرداری (4، 2، 2، 1) برای چهار مرحله (stage) و یک MHSA استاندارد تشکیل شده است. انتشار محلی با یک کانولوشن ترانهاده شده تفکیکپذیر عمقی با اندازه هسته و گام برابر با نرخ نمونهبرداری مورد استفاده در توجه پراکنده سراسری پیاده میشود.
شما میتوانید کد مورد نیاز برای پیادهسازی معماری EdgeViT را در این لینک ببینید یا به ریپازیتوری رسمی این مدل سری بزنید.
⏱︎ تاریخ نگارش: ۱۳ آبان ۱۴۰۳
دیدگاهها