
بررسی و پیادهسازی مقاله MobileNet
در این پست قصد داریم به بررسی و پیادهسازی مقاله MobileNet بپردازیم.
در سال ۲۰۱۷ محققانی از گوگل مجموعهای از مدلهای کارآمد تحت عنوان MobileNets را برای اجرای برنامههای بینایی ماشین بر روی موبایل و سایر دستگاههای تعبیه شده ارائه کردند. MobileNet بر اساس یک معماری کارآمد از فیلترهای کانولوشنی تفکیکپذیر عمقی برای ساخت شبکههای عصبی عمیق سبک وزن استفاده میکند. در این معماری از دو هایپرپارامتر ساده نیز استفاده میشود که به طور کارآمد بین تاخیر و دقت مدل مصالحه ایجاد میکند و با تغییر آنها میتوان دقت یا سرعت مدل را بهبود داد. در ادامه به بررسی و پیادهسازی این معماری خواهیم پرداخت. باید توجه داشت که بعد از MobileNet تا کنون سه نسخه دیگر از آن (MobileNetV2 – MobileNetV3 – MobileNetV4) نیز ارائه شده است که در این پست به آنها پرداخته نخواهد شد اما برای مطالعه بیشتر میتوانید به لینک قرار داده شده برای هر یک مراجعه نمایید.
فیلترهای تفکیکپذیر عمقی
مدل MobileNet بر اساس فیلترهای کانولوشنی تفکیکپذیر عمقی بنا شده است. نحوه کار بدین صورت است که یک فیلتر کانولوشن استاندارد به یک فیلتر کانولوشن عمقی (depthwise) و یک فیلتر کانولوشن 1×1 به نام کانولوشن نقطهای (pointwise) شکسته میشود. فیلتر کانولوشن عمقی (depthwise) یک فیلتر واحد را برای هر کانال ورودی اعمال می کند، سپس کانولوشن نقطهای (pointwise) یک کانولوشن 1×1 را بر روی خروجیهای کانولوشن عمقی اعمال میکند تا آنها را با یکدیگر ترکیب کند. این کار باعث میشود تا بار محاسباتی و اندازه مدل کاهش یابد. در شکل زیر نحوه تقسیم فیلترهای کانولوشنی عادی (الف) به فیلترهای کانولوشنی عمقی (ب) و فیلترهای کانولوشنی نقطهای (ج) نشان داده شده است.
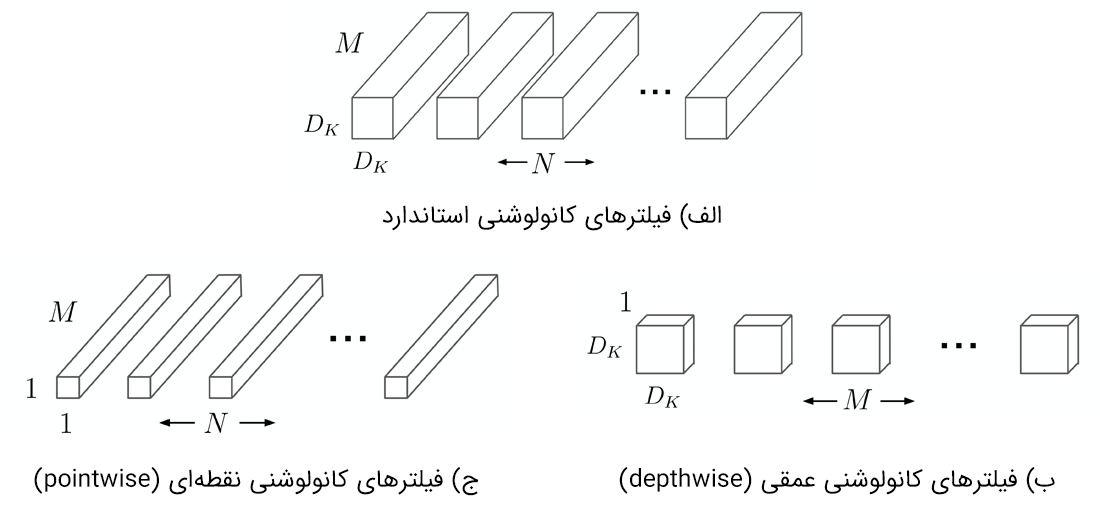
ساختار شبکه MobileNet
ساختار شبکه MobileNet در جدول زیر نشان داده شده است. پس از تمامی لایهها (به جز لایه FC آخر) از batch normalization و ReLU نیز استفاده شده است که در جدول زیر نشان داده نشدهاند.
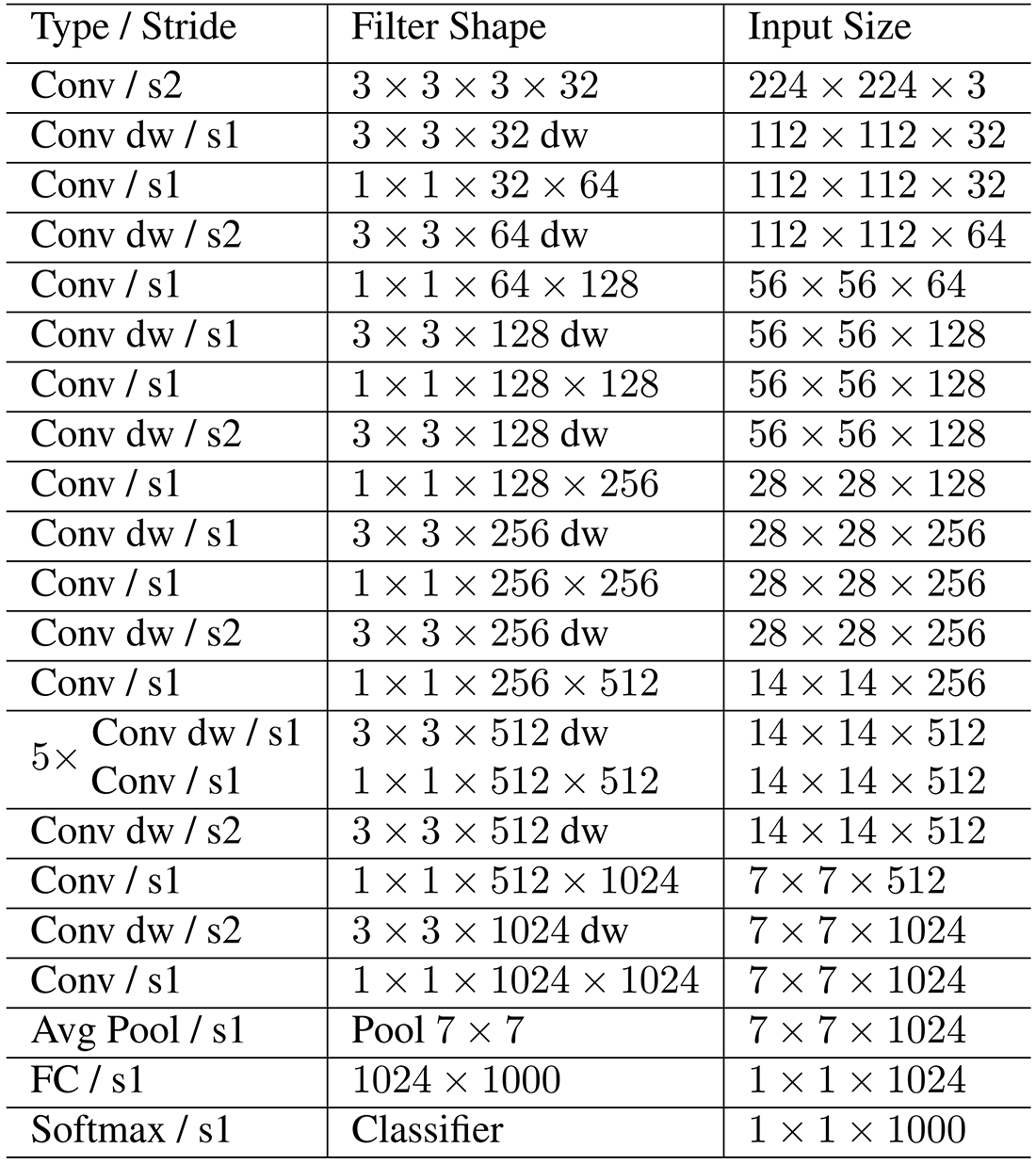
ضریب عرض: مدلهای کوچکتر
اگرچه معماری پایه MobileNet خود یک معماری سبک و با تأخیر کم است، ممکن است در بسیاری از اوقات یک برنامه کاربردی خاص نیاز به مدلی کوچکتر و سریعتر داشته باشد. به منظور ساخت این مدلهای کوچکتر، پارامتری ساده به نام ضریب عرض یا α در این مقاله معرفی شده است. نقش ضریب عرض α کوچک کردن یک شبکه به طور یکنواخت در هر لایه است. برای یک لایه و ضریب عرض معین α، تعداد کانالهای ورودی M تبدیل به αM و تعداد کانالهای خروجی N تبدیل به αN میشود که α ∈ (0, 1] میباشد.
ضریب رزولوشن: بازنمایی کاهش یافته
دومین هایپرپارامتر برای کاهش هزینه محاسباتی، ضریب رزولوشن ρ است. این ضریب به تصویر ورودی اعمال میشود و بازنمایی داخلی هر لایه متعاقباً با همان ضریب کاهش مییابد. در عمل ρ به طور ضمنی با تغییر وضوح تصویر ورودی تنظیم میشود. بنابراین با تغییر رزولوشن استاندارد ورودی (۲۲۴) به مقادیر دیگر (۱۹۲، ۱۶۰ یا ۱۲۸) میتوان ρ را تنظیم نمود.
پیادهسازی
مدل MobileNet توسط محققینی از گوگل توسعه یافته است و بنابراین پیادهسازی آن نیز در فریمورک تنسورفلو (که متعلق به گوگل میباشد) موجود است. برای استفاده از این مدل آماده و از پیش آموزش داده شده تنها نیاز است تا از دستورات زیر استفاده نمایید.
در قطعه کد فوق ابتدا مدل MobileNet با وزنهای از پیش آموزش داده شده بر روی دیتاست ImageNet، لود میشود و سپس بر روی یک تصویر دلخواه عمل پیشبینی انجام میشود. در مثال بالا ما از تصویر یک نوع سگ (Pug) استفاده کردهایم که پیشبینی مدل برای کلاس این تصویر نیز همان Pug خواهد بود.
در بالا نحوه استفاده از مدل آماده MobileNet در کتابخانه تنسورفلو را دیدیم. اما اگر قصد پیادهسازی این مدل از پایه را داشته باشیم باید مراحل زیر را طی کنیم.
ابتدا نیاز است تا ساختار مدل را طبق جدول آورده شده در بالا تعریف کنیم. تنها تفاوت موجود در اینجا در لایه آخر مدل (لایه FC) میباشد که به جای ۱۰۰۰ نود از یک نود استفاده کردهایم و دلیل آن نیز این است که ما در این بخش میخواهیم مدل خود را بر روی دیتاست کوچکتری به نام Cats vs. Dogs آموزش دهیم که بر خلاف ImageNet (که هزار کلاس دارد) تنها دو کلاس دارد و بنابراین تنها به یک نود در لایه آخر نیاز است. همچنین در اینجا تابع فعالساز لایه آخر (به جای Softmax) Sigmoid خواهد بود.
اکنون نیاز است تا دیتاست مورد نظر خود را برای آموزش مدل آماده کنیم. همانطور که پیشتر نیز گفته شد ما در اینجا از دیتاست Cats vs. Dogs استفاده میکنیم.
حال مدل را کامپایل کرده و آموزش میدهیم. با توجه به اینکه دیتاست ما دو کلاسه است از binary_crossentropy برای تابع loss استفاده کردهایم. بهینهساز نیز با توجه به توضیحات مقاله rmsprop انتخاب شده است. همچنین از Early Stopping با patience سه استفاده شده است. طبق تنظیمات فوق آموزش مدل ما بعد از ۱۲ Epoch متوقف شد و به دقت نزدیک ۹۷ درصد رسید.
پس از آموزش مدل میتوانیم آن را ارزیابی کنیم. دقت مدل آموزش دیده ما بر روی دیتاست تست چیزی حدود ۸۸ درصد شد. همچنین برای تصویر تست دلخواه توانست به درستی کلاس آن را تشخیص دهد. شما میتوانید با دادن تصاویر دلخواه دیگر به مدل، خروجی آن را مشاهده کنید.
در بالا قطعه کدهای لازم برای پیادهسازی مدل MobileNet از پایه و همچنین آموزش آن بر روی دیتاستی دلخواه آورده شد. میتوانید کدهای لازم برای پیادهسازی، آموزش و ارزیابی MobileNet را از گیت هاب نیز دانلود کنید. ما برای پیادهسازی از فریمورک تنسورفلو استفاده کردیم اما میتوان این مدل را با فریمورکهای دیگری از جمله پایتورچ نیز پیادهسازی کرد. شما میتوانید پیادهسازی MobileNet با پایتورچ به همراه تمامی کدهای فوق و نتیجه اجرای آنها را در این نوت بوک کولب مشاهده نمایید. همچنین لازم به ذکر است که ما در پیادهسازی کدهای فوق از این پست در Kaggle کمک گرفتیم.
⏱︎ تاریخ نگارش: ۲۵ تیر ۱۴۰۳
دیدگاهها